Github Copilot Agent模式使用经验分享
Categories:
本文总结了如何使用 GitHub Copilot Agent 模式,并分享实际操作经验。
前置设置
- 使用 VSCode Insider;
- 安装 GitHub Copilot(预览版)插件;
- 选择 Claude 3.7 Sonnet(预览版)模型,该模型在代码编写方面表现出色,同时其它模型在速度、多模态(如图像识别)及推理能力上具备优势;
- 工作模式选择 Agent。
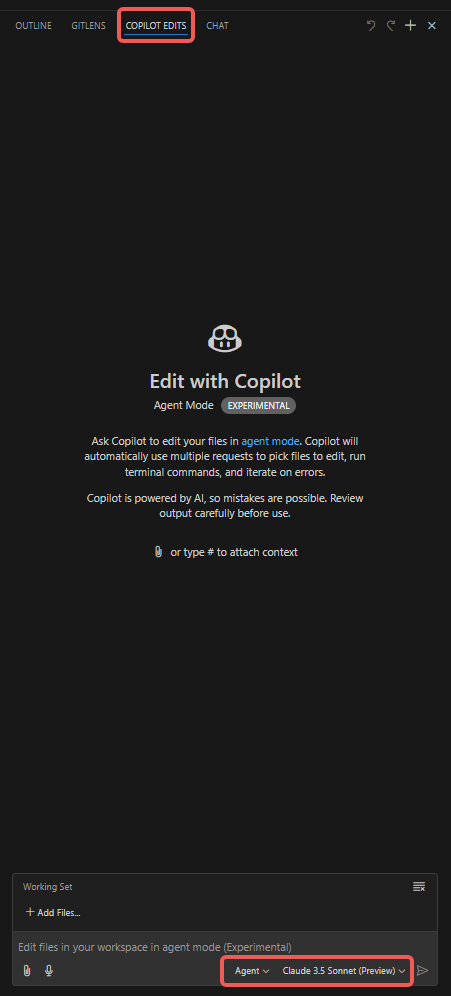
操作步骤
- 打开 “Copilot Edits” 选项卡;
- 添加附件,如 “Codebase”、“Get Errors”、“Terminal Last Commands” 等;
- 添加 “Working Set” 文件,默认包含当前打开的文件,也可手动选择其他文件(如 “Open Editors”);
- 添加 “Instructions”,输入需要 Copilot Agent 特别注意的提示词;
- 点击 “Send” 按钮,开始对话,观察 Agent 的表现。
其它说明
- VSCode 通过语言插件提供的 lint 功能可以产生 Error 或 Warning 提示,Agent 能自动根据这些提示修正代码。
- 随着对话的深入,Agent 生成的代码修改可能会偏离预期。建议每次会话都聚焦一个明确的主题,避免对话过长;达到短期目标后结束当前会话,再启动新任务。
- “Working Set” 下的 “Add Files” 提供 “Related Files” 选项,可推荐相关文件。
- 注意控制单个代码文件的行数,以免 token 消耗过快。
- 建议先生成基础代码,再编写测试用例,便于 Agent 根据测试结果调试和自我校验。
- 为限制修改范围,可在 settings.json 中添加如下配置,只修改指定目录下的文件, 仅供参考:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "只需修改 ./script/ 目录下的文件,不修改其他目录下的文件."
},
{
"text": "若目标代码文件行数超过 1000 行,建议将新增函数置于新文件中,通过引用调用;如产生的修改导致文件超长,可暂不严格遵守此规则."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "在现有单元测试文件中生成测试用例."
},
{
"text": "代码修改后务必运行测试用例验证."
}
],
常见问题
输入需求得不到想要的业务代码
需要将大任务拆分成较小的任务, 每次会话只处理一个小任务. 这是由于大模型的上下文太多会导致注意力分散.
喂给单次对话的上下文, 需要自己揣摩, 太多和太少都会导致不理解需求.
DeepSeek 模型解决了注意力分散问题, 但需要在 cursor 中使用 Deepseek API. 不清楚其效果如何.
响应缓慢问题
需要理解 token 消耗机制, token 输入是便宜且耗时较短的, token 输出贵很多, 且明显更缓慢.
假如一个代码文件非常大, 实际需要修改的代码行只有三行, 但由于上下文多, 输出也多, 会导致 token 消耗很快, 且响应缓慢.
因此, 必须要考虑控制文件的大小, 不要写很大的文件和很大的函数. 及时拆分大文件, 大函数, 通过引用调用.
业务理解问题
理解问题或许有些依赖代码中的注释, 以及测试文件, 代码中补充足够的注释, 以及测试用例, 有助于 Copilot Agent 更好的理解业务.
Agent 自己生成的业务代码就有足够多的注释, 检视这些注释, 就可以快速判断 Agent 是否正确理解了需求.
生成大量代码需要 debug 较久
可以考虑在生成某个特性的基础代码后, 先生成测试用例, 再调整业务逻辑,这样 Agent 可以自行进行调试,自我验证.
Agent 会询问是否允许运行测试命令, 运行完成后会自行读终端输出, 以此来判断代码是否正确. 如果不正确, 会根据报错信息进行修改. 循环往复, 直到测试通过.
也就是需要自己更多理解业务, 需要手动写的时候并不太多, 如果测试用例代码和业务代码都不正确, Agent 既不能根据业务写出正确用例, 也不能根据用例写出正确业务代码, 这种情况才会出现 debug 较久的情况.
总结
理解大模型的 token 消耗机制, 输入的上下文很便宜,输出的代码较贵,文件中未修改的代码部分可能也算作输出, 证据是很多无需修改的代码也会缓慢输出.
因此应尽量控制单文件的大小, 可以在使用中感受 Agent 在处理大文件和小文件时, 响应速度上的差异, 这个差异是非常明显的.