This is the multi-page printable view of this section. Click here to print.
Programmers
- Learning Architecture via Prompts
- AI-assisted programming
- Network
- A Few Ways to Safely Use Public IPv6
- Using Common DDNS Subdomains May Cause China Telecom Broadband Service Degradation
- Compliance Discussion of Reverse Proxy in Home Networks
- Some Characteristics of China Telecom IPv6
- Why we should not think of UDP in terms of TCP
- Troubleshooting Linux Network Issues
- How to Improve Network Experience with a Self-Hosted DNS Service
- Bypassing ChatGPT VPN Detection
- Chat
- Which Languages Are Best for Multilingual Projects
- Third-party Library Pitfalls
- Design Specification Template
- Command Line Syntax Conventions
- Meanings of brackets in man pages
- Huawei C++ Coding Standards
- linux
- Troubleshooting
- windows
- Windows SSH Remote Login
- Understanding Windows Networking_WFP
- Understanding Windows Event Tracing (ETW)
- wireguard configuration
- Windows Blocking Network Traffic Capture
- Windows Firewall Management – netsh
- Windows Resources
- Windows Guide
- window-message
- Win-to-go
- environment
- How Many Principles of Design Patterns Are There?
- Cross-Platform Content Publishing Tool — A Review of "蚁小二"
- Jianshu Writing Experience
Learning Architecture via Prompts
Android Development
Preface: You might find this prompt somewhat abstract at first, but a little patience goes a long way—knowledge must first be memorized, then understood. A few exceptional minds grasp concepts instantly without practice, but for most of us, hands-on experience is essential. Through concrete implementation we generalize ideas, turning knowledge into second nature. Try committing these prompts to memory for now; they can guide everyday work, where you’ll gradually absorb their distilled wisdom. Feel free to share any thoughts you have.
Cursor Rule
// Android Jetpack Compose .cursorrules
// Flexibility Notice
// Note: This is a recommended project structure—stay flexible and adapt to the existing project layout.
// If the project follows a different organisation style, do not force these structural patterns.
// While applying Jetpack Compose best practices, prioritise maintaining harmony with the current architecture.
// Project Architecture & Best Practices
const androidJetpackComposeBestPractices = [
"Adapt to the existing architecture while upholding clean code principles",
"Follow Material Design 3 guidelines and components",
"Implement clean architecture with domain, data, and presentation layers",
"Use Kotlin coroutines and Flow for asynchronous operations",
"Use Hilt for dependency injection",
"Adhere to unidirectional data flow with ViewModel and UI State",
"Use Compose Navigation for screens management",
"Implement proper state hoisting and composition",
];
// Folder Structure
// Note: This is a reference structure—adapt it to your project’s existing organisation
const projectStructure = `app/
src/
main/
java/com/package/
data/
repository/
datasource/
models/
domain/
usecases/
models/
repository/
presentation/
screens/
components/
theme/
viewmodels/
di/
utils/
res/
values/
drawable/
mipmap/
test/
androidTest/`;
// Compose UI Guidelines
const composeGuidelines = `
1. Use remember and derivedStateOf appropriately
2. Implement proper recomposition optimisation
3. Apply the correct order of Compose modifiers
4. Follow naming conventions for composable functions
5. Implement proper preview annotations
6. Use MutableState for correct state management
7. Implement proper error handling and loading states
8. Leverage MaterialTheme for proper theming
9. Follow accessibility guidelines
10. Apply proper animation patterns
`;
// Testing Guidelines
const testingGuidelines = `
1. Write unit tests for ViewModels and UseCases
2. Implement UI tests using the Compose testing framework
3. Use fake repositories for testing
4. Achieve adequate test coverage
5. Use proper test coroutine dispatchers
`;
// Performance Guidelines
const performanceGuidelines = `
1. Minimise recompositions with proper keys
2. Use LazyColumn and LazyRow for efficient lazy loading
3. Implement efficient image loading
4. Prevent unnecessary updates with proper state management
5. Follow correct lifecycle awareness
6. Implement proper memory management
7. Use adequate background processing
`;
References
AI-assisted programming
Embrace change.
Why Has GitHub Copilot Become Dumber?
Article Title One
Paste the full content of the first article here...
Article Title Two
Paste the full content of the second article here...
The AI Assistant Is Way Smarter Than Me
For a middle-aged man who has been coding for ten years, once went abroad for a gilded stint, and still cares about saving face, admitting that AI is better than me is downright embarrassing.
The total monthly cost of all the AI tools I use doesn’t exceed 200 RMB, yet my boss pays me far more than that.
I fully expect earfuls of ridicule:
“That’s only you.”
“That’s what junior devs say.”
“It only handles the easy stuff.”
“It can’t do real engineering.”
“Its hallucinations are severe.”
“It’s not fit for production.”
My experience with AI tools has been robust enough to let me shrug off such mockery. This article won’t promote any specific tool; its main purpose is to create an echo in your thoughts, since I learn so much from each comment thread.
I was among the first users of GitHub Copilot; I started in the beta and, once it ended, renewed for a year without hesitation—and I’m still using it today. I no longer get excited when I solve a thorny problem on my own, nor do I take pride in “elegant code.” The only thing that thrills me now is when the AI accurately understands what I am trying to express, when my AI assistant fulfills my request—and exceeds my expectations.
Of the experience I accumulated over the past decade, what turns out to be most useful with AI tools is:
- Logic
- Design patterns
- Regular expressions
- Markdown
- Mermaid
- Code style
- Data structures and algorithms
More specifically:
- A major premise, a minor premise, and a suitable relation between them.
- Create dependencies cautiously and strictly prevent circular ones.
- Do not add relations unless necessary; do not broaden the scope of relations unless necessary.
- Strictly control the size of logic blocks.
- Use regex-based searches and, following naming conventions, generate code that lends itself to such searches.
- Generate Mermaid diagrams, review and fine-tune them, then use Mermaid diagrams to guide code generation.
- Use the names of data structures and algorithms to steer code generation.
I have spent a lot of time contributing to various open-source projects—some in familiar domains, others not. It’s experience that lets me ramp up quickly. You’ll notice that great projects all look alike, while lousy projects are lousy in their own distinct ways.
If my memory gradually deteriorates and I start forgetting all the knowledge I once accumulated, yet still have to keep programming to put food on the table, and if I could write only the briefest reminder to myself on a sticky note, I would jot: Google "How-To-Ask-Questions"
Are humans smarter than AI? Or are only some humans smarter than some AI?
I have to be honest: puffing up my own ego brings no real benefit. As the title says, this article tears off the façade and exposes what I truly feel inside—that AI is better than me, far better. Whenever doubts about AI creep in, I’ll remind myself:
Is AI dumber than humans? Or are only some humans dumber than some AI? Maybe I need to ask the question differently?
Network
- Network
Network
- Bypass firewall
- Network troubleshooting
A Few Ways to Safely Use Public IPv6
Some people need to “go home” via public IPv6. Unlike Tailscale/Zerotier et al., which rely on NAT traversal to create direct tunnels, native IPv6 offers a straight-through connection. Cellular networks almost always hand out global IPv6 addresses, so “going home” is extremely convenient.
I previously posted Using Common DDNS Sub-domains on Home Broadband May Downgrade Telecom Service describing a pitfall with IPv6: domains get crawled. Exposing your domain is basically the same as exposing your IPv6 address. Once scanners find open services and inbound sessions pile up, the ISP may silently throttle or downgrade your line.
That thread mentioned domain scanning but not cyberspace scanning—which ignores whatever breadcrumbs you leave and just brute-forces entire address blocks. This is much harder to defend against.
Cyberspace scanning usually includes the following steps:
- Host-alive detection using ARP, ICMP, or TCP to list responsive IPs.
- Port / service discovery to enumerate open ports and identify service names, versions, and OS signatures.
- Operating-system fingerprinting by analyzing packet replies.
- Traffic collection to spot anomalies or attack patterns.
- Alias resolution mapping multiple IPs to the same router.
- DNS recon reverse-resolving IPs to domain names.
Below are a few methods to stay off those scanners:
- Have your internal DNS server never return AAAA records.
- Allow internal services to be reached only via domain names, never by raw IP.
- Use a private DNS service such as AdGuardPrivate.
Prevent AAAA Records on the Internal DNS
When you browse the web, every outbound connection can leak your source IPv6. If a firewall isn’t in place, that address enters the scanners’ high-priority IP pools.
Even scanning only the last 16 bits of a /56 prefix becomes a smaller task once the prefix is leaked.
After years of IPv6 use, I have seen no practical difference between IPv6 and IPv4 for day-to-day browsing. So we can sacrifice IPv6 for outbound traffic and reserve it solely for “go home” access.
How to block AAAA records
Configure your internal DNS resolver to drop all AAAA answers.
Most home setups run AdGuard Home—see the screenshot:
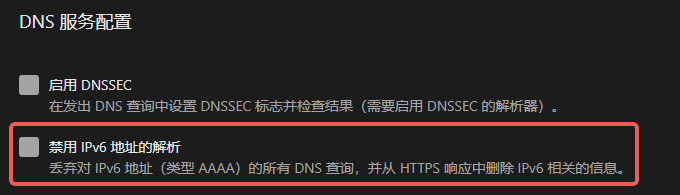
Once applied, local devices reach the outside world over IPv4 only.
Never Expose Services by IP
Exposing a service on a naked port makes discovery trivial. When you start a service, avoid binding to 0.0.0.0 and ::; almost every tutorial defaults to 127.0.0.1 plus ::1 for good reason—listening on public addresses is risky.
Reverse-proxy only by domain name
nginx example
Set server_name to an actual hostname instead of _ or an IP.
server {
listen 80;
server_name yourdomain.com; # replace with your real domain
# 403 for anything not the correct hostname
if ($host != 'yourdomain.com') {
return 403;
}
location / {
root /path/to/your/web/root;
index index.html index.htm;
}
# additional config...
}
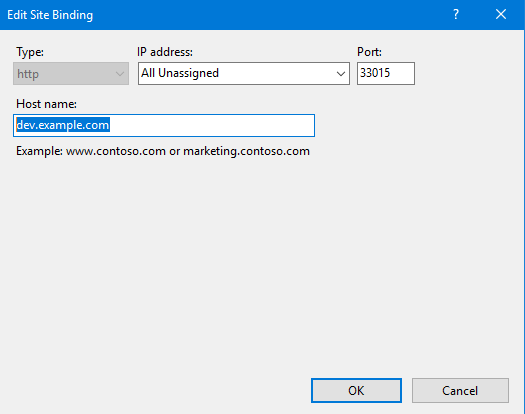
IIS example
Remember to specify the exact hostname—never leave the host field blank.
Use a private DNS service
Create spoofed hostnames that resolve only inside your own DNS.
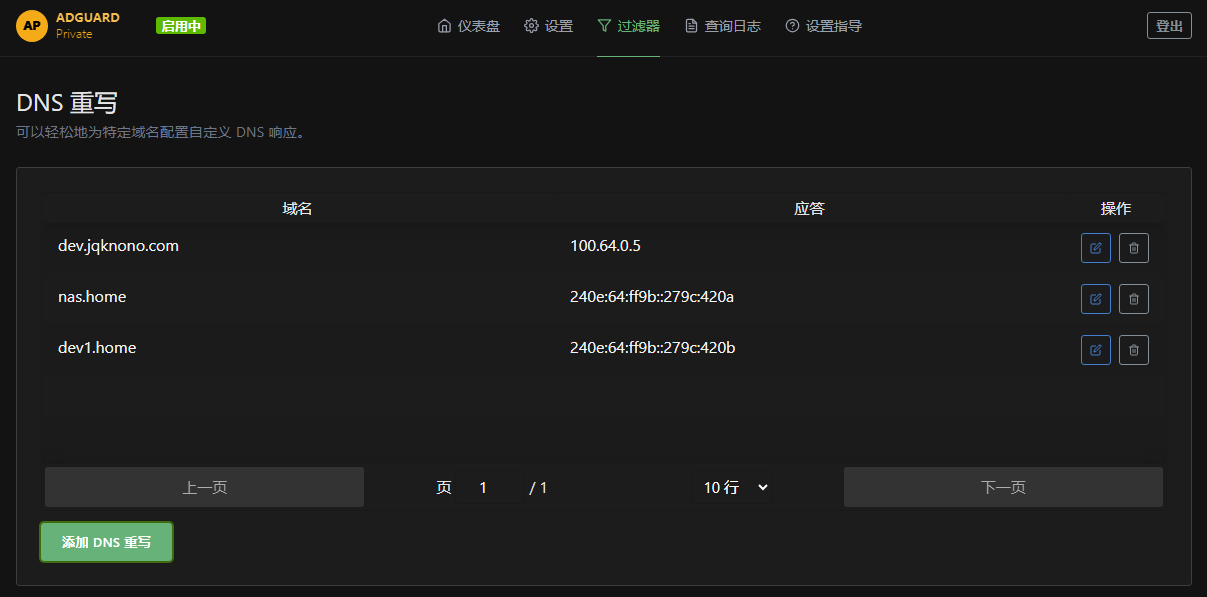
Benefits:
- Hostnames can be anything—no need to buy a public domain.
- If a fake hostname leaks, the attacker still has to point their DNS resolver at your private server.
- Scanning the IP alone is useless: one must also (a) know the fake name, (b) set their resolver to your DNS, (c) include that name in each request’s Host header. All steps have to succeed.
sequenceDiagram
participant Scanner as Scanner
participant DNS as Private DNS
participant Service as Internal Service
Scanner->>DNS: 1. Find private DNS address
Scanner->>DNS: 2. Query fake hostname
DNS-->>Scanner: 3. Return internal IP
Scanner->>Service: 4. Construct Host header
Note right of Service: Denied if Host ≠ fake hostname
alt Correct Host
Service-->>Scanner: 5a. Response
else Wrong Host
Service-->>Scanner: 5b. 403
endThis significantly increases the scanning cost.
You can deploy AdGuardPrivate (almost a labeled AdGuard Home) or Tencent’s dnspod purely for custom records. Functionality differs, so evaluate accordingly.
Summary
Prevent the internal DNS from returning AAAA records
- Pre-reqs
- Public IPv6 prefix
- Internal DNS resolver
- Steps
- Drop AAAA answers
- Pre-reqs
Reach internal services only via domain names
- Pre-reqs
- You own a domain
- Registrar supports DDNS
- Local reverse proxy already running
- Steps
- Enable DDNS task
- Host-based access only
- Pre-reqs
Spin up a private DNS
- Pre-reqs
- Private DNS service with custom records and DDNS
- Steps
- Enable DDNS task
- Map fake hostnames to internal services
- Pre-reqs
Finally:
- Tailscale/Zerotier that successfully punch through are still the simplest and safest way to go home.
- Don’t hop on random Wi-Fi—you’ll give everything away in one shot. Grab a big-data SIM and keep your faith with the carrier for now. (Cheap high-traffic SIM? DM me. Not really.)
Using Common DDNS Subdomains May Cause China Telecom Broadband Service Degradation
I have been troubleshooting IPv6 disconnections and hole-punching failures for over three months. I’ve finally identified the root cause; here’s the story.
My First Post Asking for Help—IPv6 Disconnections
IPv6 had been working perfectly. Without touching any settings, and even though every device had its own IPv6, it suddenly lost IPv6 connectivity entirely.
curl 6.ipw.cn returned nothing, and both ping6 and traceroute6 2400:3200::1 failed.
My ONT was bridged to the router, and I could still obtain the router’s own IPv6—one that could still reach the IPv6 Internet.
I received a /56 prefix, and all downstream devices received addresses within 240e:36f:15c3:3200::/56, yet none could reach any IPv6 site.
I suspected the ISP had no route for 240e:36f:15c3:3200::, but I couldn’t prove it.
Someone suggested excessive PCDN upload traffic was the culprit, but upload volume was minimal and PCDN wasn’t enabled.
Another possibility was that using Cloudflare and Aliyun ESA reverse proxies had caused it.
My Second Post—Finding a Direct Cause
I confirmed that at least some regions of China Telecom will downswitch service when they see many inbound IPv6 HTTP/HTTPS connections, manifesting as:
- Fake IPv6: You still get a
/56, every device keeps its IPv6, but traceroute lacks a route, so IPv6 is de-facto unusable. - Fake hole- punch: Tailscale reports its connection is direct, yet latency is extreme and speed is terrible.
Every time I disabled Cloudflare/Aliyun ESA proxying and rebooted the router a few times, both real IPv6 connectivity and true direct Tailscale worked again.
Still Disconnects After Disabling Reverse Proxy
Even with proxy/CDN disabled—complete direct origin access—I still had occasional outages lasting hours.
Perhaps my domain had leaked, or bots were scanning popular subdomains with a steady HTTP attack.
When I disabled DNS resolution for the DDNS hostname outright, IPv6 came back after a while, and Tailscale hole-punching was again direct and stable.
Since then those disconnections never returned.
My Final Recommendation
Avoid using commonplace DDNS subdomains, such as:
- home.example.com
- nas.example.com
- router.example.com
- ddns.example.com
- cloud.example.com
- dev.example.com
- test.example.com
- webdav.example.com
I had used several of these; it seems they are continuously scanned by bots. The resulting flood of requests triggered China Telecom’s degradation policy, making my IPv6 unusable and blocking hole-punching.
As you already know, hiding your IP matters in network security; the same goes for protecting the domain you use for DDNS—that domain exposes your IP as well.
If you still need public services, you have two practical choices:
- Proxy/Front-end relay—traffic hits a VPS first, then your home server. Latency and bandwidth suffer because traffic takes a detour.
- DDNS direct—everything connects straight to you. Performance is much better; this is what I recommend. For personal use the number of connections rarely hits the limit, but once the domain becomes public the bots will ramp it up quickly.
Proxy Relay (Reverse Proxy)
Cloudflare Tunnel
Use Cloudflare’s Tunnel so you won’t see the dozens or hundreds of IPs typical of ordinary reverse proxies.
Tailscale or ZeroTier
Build your own VPN, put a VPS in front, and reach your LAN services through the VPN. This avoids excessive simultaneous connections.
DDNS Direct Scheme
Public DNS
Generate a random string—like a GUID—and use it as your DDNS hostname. It’s impossible to remember, but for personal use that’s acceptable. Judge for yourself.
Private DNS
Run your own DNS service, e.g.:
Configure it to serve your DDNS records; only people who can query your private DNS will resolve the custom IP.
In this model you can use common DDNS names, but take care never to expose the address of your private DNS server.
Afterthought
Rumor has it that naming a subdomain speedtest might provide a mysterious boost.
Compliance Discussion of Reverse Proxy in Home Networks
Background
About 90 days ago, I encountered an IPv6 connectivity issue with China Telecom Hubei. After long-term observation and analysis, here are the findings.
Problem Analysis
Two initial suspected causes:
PCDN usage detection
- No active use of PCDN
- Only a small amount of BitTorrent downloads
- Upload throttling has been applied, yet the problem persists
Home server acting as blog origin
- Uses Cloudflare origin rules specifying a port
- May be deemed “commercial behavior” by the ISP
After three months of validation, the issue is more likely triggered by exposing HTTP/HTTPS service ports to the public Internet.
Specific Symptoms
IPv6 anomalies:
- /56 prefix is assigned
- Devices receive global IPv6 addresses
- Yet external network access fails
- Only the router in bridge mode behind the optical modem retains normal IPv6
Tailscale connection anomalies:
- The source server reports direct connectivity but with excessive latency (~400 ms)
- Other devices go through relays and obtain lower latency (~80 ms)
ISP Policy Analysis
Telecom carriers in certain regions apply service degradation to inbound-heavy HTTP/HTTPS connections:
IPv6 service downgrade
- Addresses are still assigned
- Routing tables are missing
- Effective Internet access is blocked
P2P connection throttling
- Tailscale shows direct connections
- Actual latency is abnormally high
- Bandwidth is restricted
Solutions
Disable reverse-proxy services:
- Deactivate Cloudflare/Alibaba Cloud ESA reverse proxies
- After multiple router reboots, connectivity returns to normal
Prevent domain scanning: Avoid these common sub-domains:
- home.example.com - ddns.example.com - dev.example.com - test.example.comBest practices:
- Use a GUID to generate random sub-domains
- Refrain from predictable or common sub-domain naming
- Rotate domains periodically to reduce scanning risk
Some Characteristics of China Telecom IPv6
Some Characteristics of China Telecom IPv6
Some Characteristics of China Telecom IPv6
IPv6 has been fully rolled out nationwide; the IPv6 address pool is large enough for each of every individual’s devices to obtain its own IPv6 address.
To actually use IPv6 at home, the entire stack of devices must all support IPv6. Because the rollout has been underway for many years, virtually every device bought after 2016 already supports IPv6.
The full stack includes: metro equipment → community router → home router (ONT/router) → end device (phones, PCs, smart TVs, etc.)
This article does not discuss the standard IPv6 protocol itself; it focuses only on certain characteristics of China Telecom’s IPv6.
Address Allocation
First, the methods of address assignment. IPv6 offers three ways to obtain an address: static assignment, SLAAC, and DHCPv6.
Hubei Telecom uses SLAAC, meaning the IPv6 address is automatically assigned by the device. Because the carrier’s IPv6 pool is enormous, address conflicts are impossible.
Telecom IPv6 addresses are assigned at random and recycled every 24 h. If you need inbound access, you must use a DDNS service.
Firewall
At present it can be observed that common ports such as 80, 139, 445 are blocked—mirroring the carrier’s IPv4 firewall. This is easy to understand: operator-level firewalls do protect ordinary users who lack security awareness. In 2020, China Telecom IPv6 was fully open, but now certain common ports have been blocked.
Port 443 is occasionally accessible within the China Telecom network but blocked for China Mobile and China Unicom. Developers must keep this in mind. A service that works fine in your dev environment—or that your phone on the China Telecom network can reach—may be unreachable from a phone on a different carrier.
Based on simple firewall testing, developers are strongly advised not to trust operator firewalls. Serve your application on a five-digit port.
Furthermore, China Telecom’s firewall does not block port 22, and Windows Remote Desktop port 3389 is likewise open.
Consequently, remote login is possible—introducing obvious risks.
Once attackers obtain the IP or DDNS hostname, they can start targeted attacks; brute-force password cracking can grant control of the device. The domain name can also reveal personal information—name, address, etc.—and attackers may use social-engineering tactics to gather even more clues to speed up their intrusion.
It is recommended to disable password authentication for ssh and rely only on key-based login, or to use a VPN, or to employ a jump host for remote access.
Why we should not think of UDP in terms of TCP
- Why we should not think of UDP in terms of TCP
Why we should not think of UDP in terms of TCP?
Structural Differences
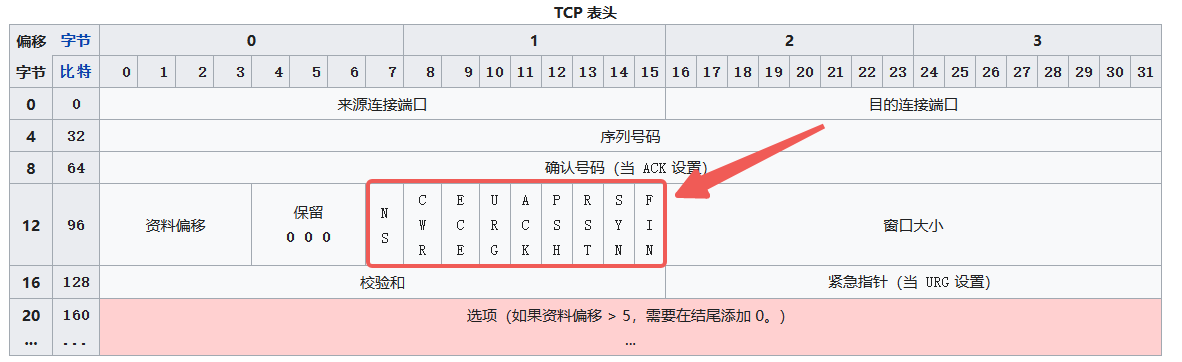

TCP has many concepts: connection establishment, resource usage, data transfer, reliable delivery, retransmission based on cumulative ACK-SACK, timeout retransmission, checksum, flow control, congestion control, MSS, selective acknowledgements, TCP window scale, TCP timestamps, PSH flag, connection termination.
UDP has virtually none of these facilities; it is only slightly more capable than the link layer in distinguishing applications. Because UDP is extremely simple, it is extremely flexible.
If it can happen, it will
Murphy’s law:
If anything can go wrong, it will.
Conventional wisdom suggests that UDP suits games, voice, and video because a few corrupt packets rarely matter. The reason UDP is chosen for these use-cases is not that it is the perfect match, but that there are unsolved problems for TCP that force services to pick the less-featured UDP. Saying “a few corrupt packets do not disturb the service” actually means that TCP worries about packet correctness while UDP does not; UDP cares more about timeliness and continuity. UDP’s defining trait is its indifference to everything TCP considers important—factors that harm real-time performance.
In code, UDP only needs one socket bound to a port to begin sending and receiving. Usually the socket lifetime matches the port lifetime.
Therefore, I can use UDP like this:
- Send random datagrams to any IP’s any port and see who replies.
- Alice sends a request from port A to port B of Bob, Bob responds from port C to Alice’s port D.
- Alice same as above, but Bob asks Charlie to answer from port C to Alice’s port D.
- Alice sends a request from port A to port B, but spoofs the source address to Charlie’s address; Bob will reply to Charlie.
- Both sides agree to open ten UDP ports and send as well as receive on each one concurrently.
Of course none of these patterns can exist in TCP, but in UDP, because they are possible, sooner or later someone will adopt them. Expecting UDP to behave like TCP is therefore idealistic; reality cannot be fully enumerated.
UDP datagrams are extremely lightweight and highly flexible; the idea of a “connection” does not exist at the protocol level, so you must invent your own notion of a UDP connection. Different definitions were tried, yet none could always unambiguously describe direction from a single datagram; we must accept ambiguity. After all, no official “UDP connection” standard exists—when parties hold different definitions, mismatched behaviours are inevitable.
UDP from the client’s viewpoint
Voice or video can suffer packet loss, but the loss pattern has very different effects on user experience. For example, losing 30 % of packets evenly or losing 30 % all within half a second produces drastically different experiences; the former is obviously preferable. However, UDP has no built-in flow control to deliberately throttle traffic. Although UDP is often described as “best-effort”, the details of that effort still determine the outcome.
UDP from the provider’s viewpoint
For TCP attacks, the client must invest computational resources to create and maintain connections—attackers thus incur costs. With UDP, the attacker’s overhead is much lower; if the goal is just to burn server bandwidth, UDP is perfect. Suppose the service buys 100 GB of unmetered traffic but only processes 10 MB/s while accepting 1 GB/s—90 % of the arriving traffic is junk, yet it is still billable. Providers should avoid such situations.
UDP from the ISP’s viewpoint
End-to-end communication comprises multiple endpoints and transit paths. We usually focus only on client and server viewpoints, but the ISP’s perspective matters too. Under DDoS, we pay attention to server capacity, ignoring the ISP’s own finite resources. The server may ignore useless requests, yet the ISP has already paid to carry them. When we perform stress tests we often report “packet loss”, overlooking that the number reflects loss along the entire path—not just at the server. ISPs drop packets as well. From the ISP’s view, the service purchased 1 MB/s, but the client send rate is 1 GB/s; they both pay nothing for the wasted bandwidth—the ISP bears the cost. To avoid that, ISPs implement UDP QoS. Compared to TCP’s congestion control, ISPs can just drop UDP. In practice the blunt approach is to block traffic on long-lived UDP ports. Field tests of WeChat calls show that each call uses multiple ports with one UDP port talking to six different UDP ports on the same server—likely a countermeasure to ISP port blocks.
Summary
UDP’s flexibility usually means there are several legitimate methods to reach a goal; as long as the program eventually communicates stably, however bizarre it may appear compared with TCP, it is “the way it is”. We therefore cannot force TCP concepts onto UDP. Even when we invent a new “UDP connection” for product design, we must expect and gracefully accept errors—the ability to tolerate errors is UDP’s core feature, an advantage deliberately chosen by the service, not a flaw we have to live with.
Further reading
Troubleshooting Linux Network Issues
Troubleshooting Tools
| Tool | Description | Usage | Note |
|---|---|---|---|
| ping | Test network connectivity | ping baidu.com | |
| traceroute | Route tracing | traceroute ip | |
| route | Routing table | route -n | |
| netstat | Network connections | netstat -ano | |
| nslookup | DNS resolution | nslookup baidu.com | |
| ifconfig | Network configuration | ifconfig | |
| arp | ARP cache | arp -a | |
| nbtstat | NetBIOS | nbtstat -n | |
| netsh | Network configuration | netsh | |
| net | Network configuration | net | |
| tcpdump | Packet capture | tcpdump | |
| wireshark | Packet capture | wireshark | |
| ip | Network configuration | ip addr show | |
| ss | Network connections | ss -tunlp | |
| netstat | View network connection state | netstat -anp | |
| tcpdump | Packet-capture utility | tcpdump -i eth0 -nn -s 0 -c 1000 -w /tmp/tcpdump.pcap | |
| iptables | Firewall | iptables -L -n -v -t nat -t mangle -t filter | |
| ss | netstat replacement | ss -anp | |
| ifconfig | View NIC information | ifconfig eth0 | |
| ip | View NIC information | ip addr show eth0 | |
| route | View routing table | route -n | |
| traceroute | View routing hops | traceroute www.baidu.com | |
| ping | Test network connectivity | ping www.baidu.com | |
| telnet | Test port connectivity | telnet www.baidu.com 80 | |
| nslookup | Domain resolution | nslookup www.baidu.com | |
| dig | Domain resolution | dig www.baidu.com | |
| arp | View ARP cache | arp -a | |
| netcat | Network debugging tool | nc -l 1234 | |
| nmap | Port-scanning tool | nmap -sT -p 80 www.baidu.com | |
| mtr | Network connectivity tester | mtr www.baidu.com | |
| iperf | Network performance tester | iperf -s -p 1234 | |
| iptraf | Network traffic monitor | iptraf -i eth0 | |
| ipcalc | IP address calculator | ipcalc | |
| iftop | Network traffic monitor | iftop -i eth0 | |
| iostat | Disk I/O monitor | iostat -x 1 10 | |
| vmstat | Virtual memory monitor | vmstat 1 10 | |
| sar | System performance monitor | sar -n DEV 1 10 | |
| lsof | Show open file usage | lsof -i:80 | |
| strace | Trace system calls | strace -p 1234 | |
| tcpflow | Packet-capture tool | tcpflow -i eth0 -c -C -p -o /tmp/tcpflow | |
| tcpick | Packet-capture tool | tcpick -i eth0 -C -p -o /tmp/tcpick | |
| tcptrace | Packet-capture tool | tcptrace -i eth0 -C -p -o /tmp/tcptrace | |
| tcpslice | Packet-capture tool | tcpslice -i eth0 -C -p -o /tmp/tcpslice | |
| tcpstat | Packet-capture tool | tcpstat -i eth0 -C -p -o /tmp/tcpstat | |
| tcpdump | Packet-capture tool | tcpdump -i eth0 -C -p -o /tmp/tcpdump | |
| tshark | Packet-capture tool | tshark -i eth0 -C -p -o /tmp/tshark | |
| wireshark | Packet-capture tool | wireshark -i eth0 -C -p -o /tmp/wireshark | |
| socat | Network debugging tool | socat -d -d TCP-LISTEN:1234,fork TCP:www.baidu.com:80 | |
| ncat | Network debugging tool | ncat -l 1234 -c ’ncat www.baidu.com 80' | |
| netperf | Network performance tester | netperf -H www.baidu.com -l 60 -t TCP_STREAM | |
| netcat | Network debugging tool | netcat -l 1234 | |
| nc | Network debugging tool | nc -l 1234 | |
| netpipe | Network performance tester | netpipe -l 1234 | |
| netkit | Network debugging tool | netkit -l 1234 | |
| bridge | Bridge tool | bridge -s |
How to Improve Network Experience with a Self-Hosted DNS Service
Network Quality vs. Network Experience
Do nothing, and you’ll already enjoy the best network experience.
First, note that “network quality” and “network experience” are two different concepts. Communication is a process involving many devices. The upload/download performance of a single device can be termed network quality, while the end-to-end behavior of the entire communication path is what we call network experience.
Measuring Network Quality
Evaluating network quality usually involves several metrics and methods. Common ones include:
- Bandwidth – the capacity to transfer data, conventionally expressed in bits-per-second. Higher bandwidth generally indicates better quality.
- Latency – the time a packet takes to travel from sender to receiver. Lower latency means faster response.
- Packet-loss rate – the proportion of packets lost en route. A lower rate suggests higher quality.
- Jitter – variability in packet arrival times. Smaller jitter means a more stable network.
- Throughput – the actual data volume successfully transported in a given period.
- Network topology – the physical or logical arrangement of network nodes; good design improves quality.
- Quality-of-Service (QoS) – techniques such as traffic shaping and priority queues that ensure acceptable service levels.
- Protocol analysis – examining traffic with tools like Wireshark to diagnose bottlenecks or errors.
Combined, these indicators give a complete picture of network performance and improvement opportunities. Carriers need these details, but ordinary users often need only a decently priced modern router—today’s devices auto-tune most of these knobs.
Measuring Network Experience
The first factor is reachability—being able to connect at all. A DNS service must therefore be:
- Comprehensive: its upstream resolvers should be authoritative and able to resolve the largest possible set of names.
- Accurate: results must be correct and free from hijacking or pollution returning advertisement pages.
- Timely: when an IP changes, the resolver must return the fresh address, not a stale record.
Next comes the network quality of the resolved IP itself.
Because service quality varies strongly with region, servers geographically closer to the client often offer better performance.
Most paid DNS providers support Geo-aware records. For example, Alibaba Cloud allows:
(1) Carrier lines: Unicom, Telecom, Mobile, CERNet, Great Wall Broadband, Cable WAN—down to province level.
(2) Overseas regions: down to continent and country.
(3) Alibaba cloud lines: down to individual regions.
(4) Custom lines: define any IP range for smart resolution.
“(distribution-map-placeholder)”
By resolving IPs based on location, distant users reach nearby servers automatically—boosting experience without them lifting a finger.
In practice, service providers optimize UX based on the client’s real address. For most users, doing nothing gives the best network experience.
Choosing Upstream Resolvers for Self-Hosted DNS
Nearly every Chinese-language guide tells you to pick large authoritative resolvers—Alibaba, Tencent, Cloudflare, Google—because they score high on reachability (comprehensive, accurate, timely). Yet they do not guarantee you the nearest server.
There’s historical context: Chinese ISPs once hijacked DNS plus plaintext HTTP to inject ads. Today, with HTTPS prevalent, this is far less common, though some last-mile ISPs may still try it. Simply switching resolvers to random IPs won’t save you from hijacks directed at UDP 53.
Another user niche cares about content filtering; some providers return bogus IPs for “special” sites. Authoritative resolvers rarely exhibit this behavior.
So three problems arise:
- IP contamination
- DNS hijacking
- Optimal service experience
Authoritative resolvers fix (1); encrypted transports (DoT/DoH/QUIC) mitigate (2).
For (3) you must go back to your carrier’s default DNS. As we said: “Do nothing, and you’ll already enjoy the best network experience.”
But if you’re a perfectionist or a special user, the sections below show how to configure AdGuard Home and Clash to satisfy all three concerns at once.
Authoritative yet “Smart” DNS
AdGuard Home Configuration
AdGuard Home (ADG) is an ad-blocking, privacy-centric DNS server. It supports custom upstream resolvers and custom rules.
ADG’s default mode is load-balancing: you list several upstreams; ADG weights them by historical response speed and chooses the fastest. In simple terms, it will favor the quickest upstream more often.
Pick the third option instead: “Fastest IP address”.
“(ui-screenshot-placeholder)”
Result: ADG tests the IPs returned by each upstream and replies with whichever has the lowest latency. Below are ordinary results for bilibili.com:
“(ordinary-results-screenshot-placeholder)”
Without this option, ADG would hand every IP back to the client: some apps pick the first, others the last, others pick at random—possibly far from optimal.
With “Fastest IP address” enabled:
“(optimized-results-screenshot-placeholder)”
That alone improves network experience.
Why isn’t “Fastest IP address” the default?
Because waiting for all upstream answers means query time equals the slowest upstream. If you mix a 50 ms Ali server with a 500 ms Google one, your upstream delay becomes ~500 ms.
So users must balance quality vs. quantity. I suggest keeping two upstreams only: one authoritative (https://dns.alidns.com/dns-query) plus your local carrier’s DNS.
Carrier DNS IPs differ by city; look yours up here or read them from your router’s status page:
“(router-dns-screenshot-placeholder)”
Clash Configuration
Users with special needs who still want optimal routing can delegate DNS handling to Clash’s dns section.
nameserver-policy lets you assign different domains to different resolvers. Example:
dns:
default-nameserver:
- tls://223.5.5.5:853
- tls://1.12.12.12:853
nameserver:
- https://dns.alidns.com/dns-query
- https://one.one.one.one/dns-query
- https://dns.google/dns-query
nameserver-policy:
"geosite:cn,private,apple":
- 202.103.24.68 # your local carrier DNS
- https://dns.alidns.com/dns-query
"geosite:geolocation-!cn":
- https://one.one.one.one/dns-query
- https://dns.google/dns-query
Meaning:
default-nameserver– used solely to resolve hostnames of DNS services in thenameserverlist.nameserver– standard resolvers for ordinary queries.nameserver-policy– overrides above resolvers for specific groups of domains.
Thanks for Reading
If this post helped you, consider giving it a thumbs-up. Comments and discussion are always welcome!
Bypassing ChatGPT VPN Detection
How to handle the ChatGPT error messages
“Unable to load site”
“Please try again later; if you are using a VPN, try turning it off.”
“Check the status page for information on outages.”
Foreword
ChatGPT is still the best chatbot in terms of user experience, but in mainland China its use is restricted by the network environment, so we need a proxy (literally a “ladder”) to reach it. ChatGPT is, however, quite strict in detecting proxies, and if it finds one it will simply refuse service. This article explains a way around that detection.
Some people suggest switching IPs to evade a block, yet the geolocations we can get from our providers already belong to supported regions, so this is not necessarily the real reason for denial of service.
Others argue that popular shared proxies are too easy to fingerprint and advise buying more expensive “uncrowded” ones, yet this is hardly a solid argument—IPv4 addresses are scarce, so even overseas ISPs often allocate ports via NAT. Blocking one address would hit a huge community, something that a service as widely used as ChatGPT surely would not design for.
For a public service, checking source-IP consistency makes more sense. Paid proxy plans typically impose data or speed limits, so most users adopt split-routing: they proxy only when the destination is firewalled, letting non-filtered traffic travel directly. This choice of paths can result in inconsistent source IPs. For example, Service A needs to talk to Domains X and Y, yet only X is firewalled; the proxy will be used for X but not Y, so A sees the same request coming from two different IPs.
Solving this source-IP inconsistency will bypass ChatGPT’s “ladder” identification.
Proxy rules usually include domain rules, IP rules, and so on.
Remember that the result of a domain resolution varies by region—if you are in place A you get a nearby server, and in place B you may get another. Therefore, DNS selection matters.
DNS Selection
Today there are many DNS protocols; UDP:53 is so outdated and insecure that China lists DNS servers as a top-level requirement for companies. Such rules arose from decades of carriers employing DNS hijacking plus HTTP redirection to insert advertisements, deceiving many non-tech-savvy users and leading to countless complaints. Although today Chrome/Edge automatically upgrade to HTTPS and mark plain HTTP as insecure, many small neighbourhood ISPs and repackaged old Chromium versions persist, so DNS and HTTP hijacking still occur.
Hence we need a safe DNS protocol to avoid hijacking. In my experience Alibaba’s public 223.5.5.5 works well. Of course, when I mention 223.5.5.5 I do not mean plain UDP but DoH or DoT. Configure with tls://223.5.5.5 or https://dns.alidns.com/dns-query.
Alidns rarely gets poisoned—only during certain sensitive periods. You can also use my long-term self-hosted resolver tls://dns.jqknono.com, upstreaming 8.8.8.8 and 1.1.1.1, with cache acceleration.
Domain Rules
The detection page first visited runs probing logic, sending requests to several domains to check the source IP, so domain routing must remain consistent.
Besides its own, ChatGPT relies on third-party domains such as auth0, cloudflare, etc.
Add the following rules by hand:
# openai
- DOMAIN-SUFFIX,chatgpt.com,PROXY
- DOMAIN-SUFFIX,openai.com,PROXY
- DOMAIN-SUFFIX,openai.org,PROXY
- DOMAIN-SUFFIX,auth0.com,PROXY
- DOMAIN-SUFFIX,cloudflare.com,PROXY
How to test domain rules
The domains above may evolve as ChatGPT’s services change; here is how to discover them yourself.
- Open a private/Incognito window to avoid caches/cookies.
- Press
F12to open DevTools, switch to theNetworktab. - Visit
chat.openai.comorchatgpt.com. - The following screenshot shows the domains used at the time of writing:
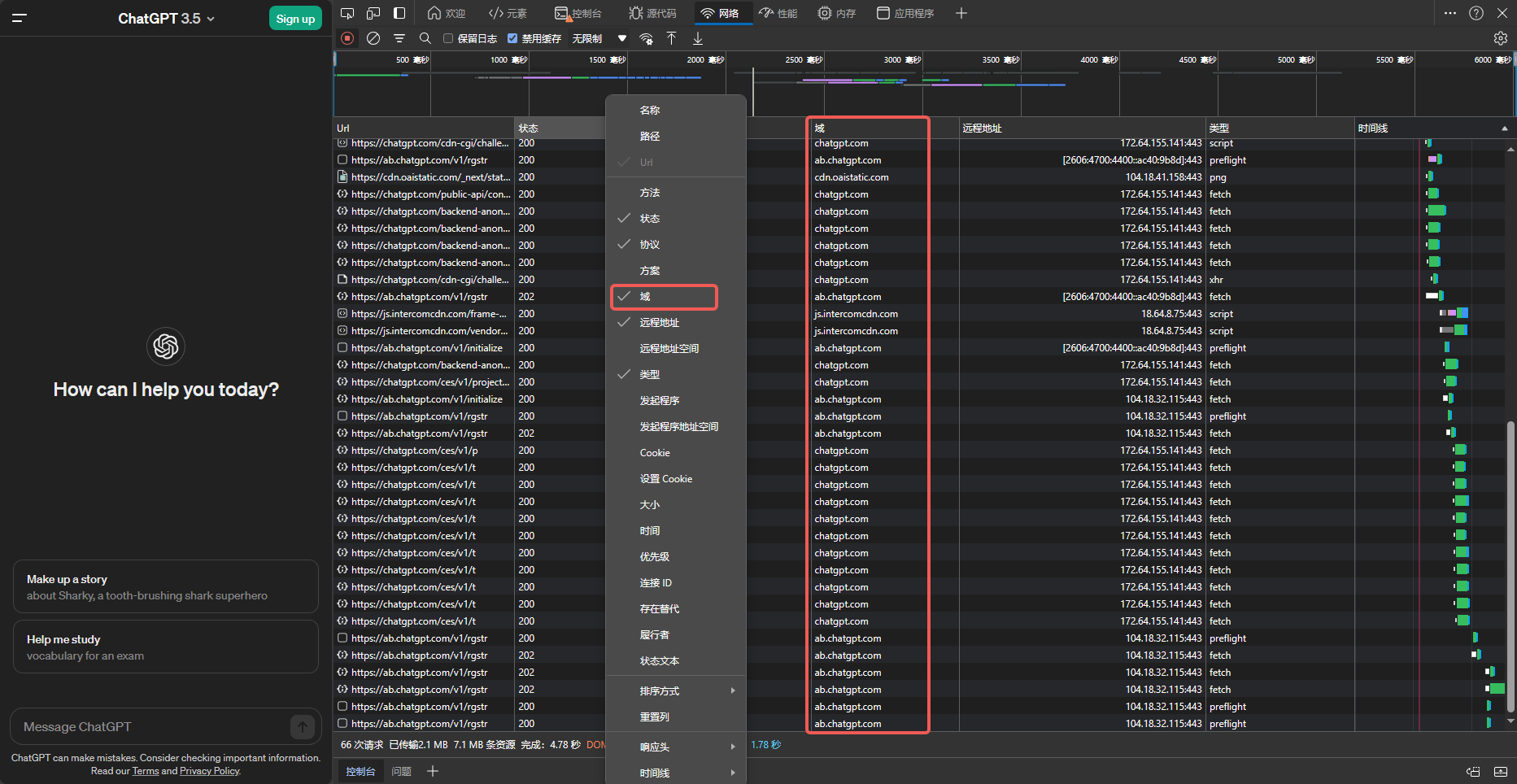
Adding just those domains may still be insufficient. Inspect each aborted request: the challenge response’s Content-Security-Policy lists many domains. Add every one to the proxy policy.
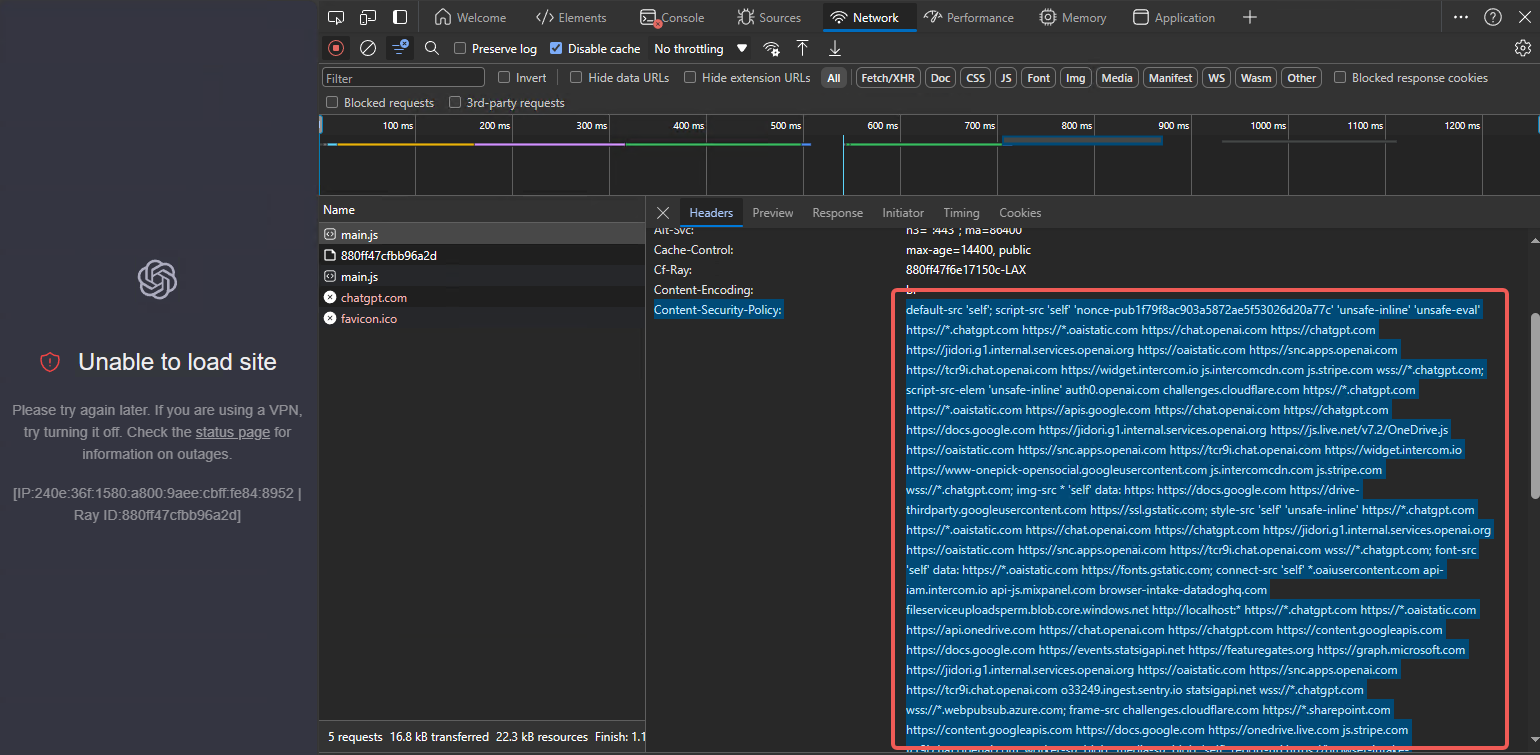
# openai
- DOMAIN-SUFFIX,chatgpt.com,PROXY
- DOMAIN-SUFFIX,openai.com,PROXY
- DOMAIN-SUFFIX,openai.org,PROXY
- DOMAIN-SUFFIX,auth0.com,PROXY
- DOMAIN-SUFFIX,cloudflare.com,PROXY
# additional
- DOMAIN-SUFFIX,oaistatic.com,PROXY
- DOMAIN-SUFFIX,oaiusercontent.com,PROXY
- DOMAIN-SUFFIX,intercomcdn.com,PROXY
- DOMAIN-SUFFIX,intercom.io,PROXY
- DOMAIN-SUFFIX,mixpanel.com,PROXY
- DOMAIN-SUFFIX,statsigapi.net,PROXY
- DOMAIN-SUFFIX,featuregates.org,PROXY
- DOMAIN-SUFFIX,stripe.com,PROXY
- DOMAIN-SUFFIX,browser-intake-datadoghq.com,PROXY
- DOMAIN-SUFFIX,sentry.io,PROXY
- DOMAIN-SUFFIX,live.net,PROXY
- DOMAIN-SUFFIX,live.com,PROXY
- DOMAIN-SUFFIX,windows.net,PROXY
- DOMAIN-SUFFIX,onedrive.com,PROXY
- DOMAIN-SUFFIX,microsoft.com,PROXY
- DOMAIN-SUFFIX,azure.com,PROXY
- DOMAIN-SUFFIX,sharepoint.com,PROXY
- DOMAIN-SUFFIX,gstatic.com,PROXY
- DOMAIN-SUFFIX,google.com,PROXY
- DOMAIN-SUFFIX,googleapis.com,PROXY
- DOMAIN-SUFFIX,googleusercontent.com,PROXY
IP Rules
If the site still refuses to load after the steps above, IP-based detection may also be in play. Below are some IPs I intercepted; they may not fit every region, so test on your own.
# openai
- IP-CIDR6,2606:4700:4400::6812:231c/96,PROXY
- IP-CIDR,17.253.84.253/24,PROXY
- IP-CIDR,172.64.152.228/24,PROXY
- IP-CIDR,104.18.35.28/16,PROXY
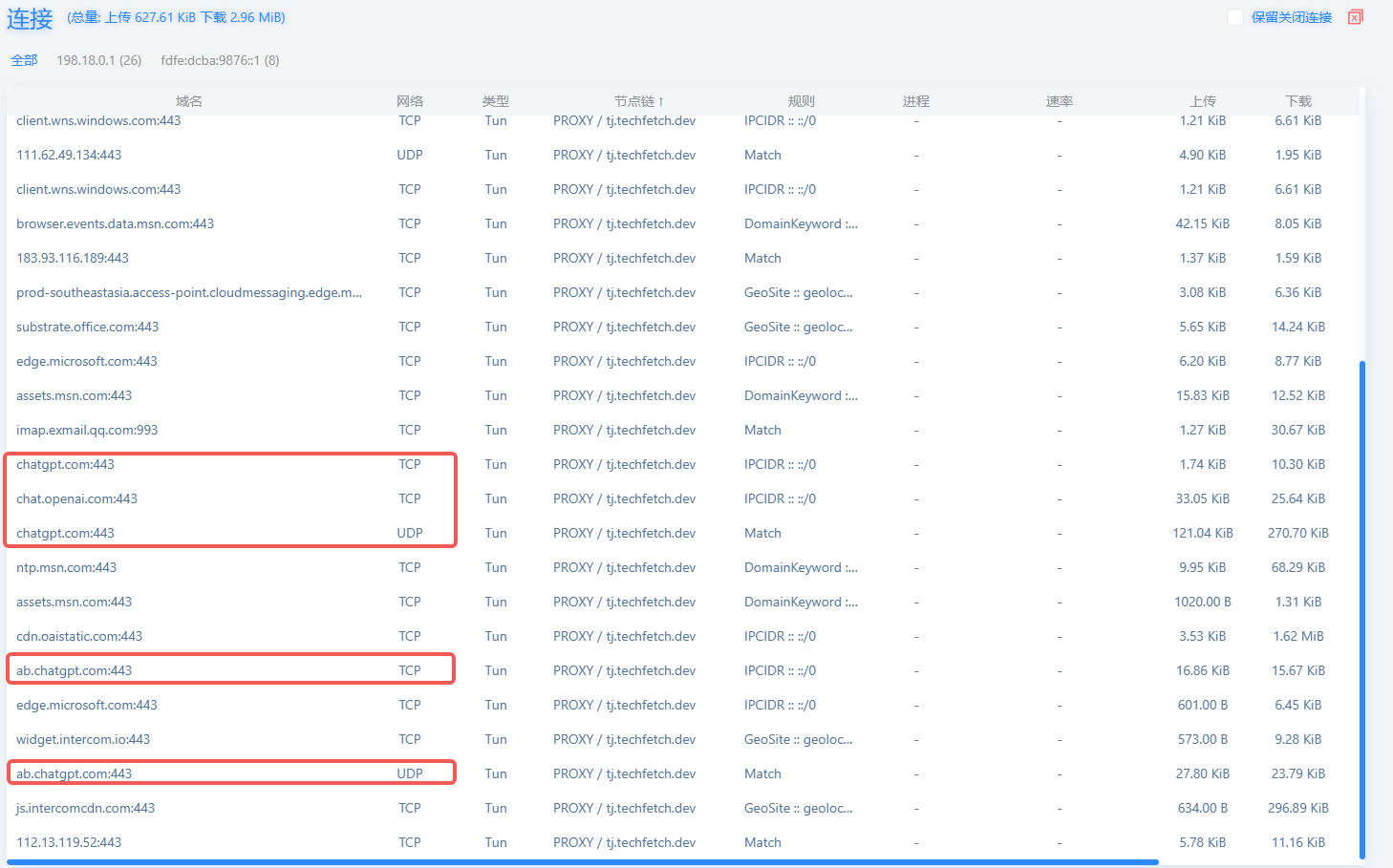
How to test IP rules
Know your proxy tool. Open its connection log, watch the new connections as you reproduce the steps, then add the IPs you see.
A quick guide:
- Open a private/Incognito window.
- Visit
chat.openai.comorchatgpt.com. - Monitor the new connections in your proxy client and copy their IPs into rules.
Protocol Rules
QUIC is an encrypted UDP protocol, and ChatGPT makes heavy use of QUIC traffic. Therefore both client and server must support UDP forwarding; many do not. Even with support, you must explicitly enable it—some clients default to not proxy UDP traffic. If unsure about UDP, either block QUIC in the proxy client or disable it in the browser; the browser will automatically fall back to HTTP/2 over TCP. QUIC provides smoother performance; feel free to experiment.
The simplest config – whitelist mode
Set direct connections only for Chinese IPs and proxy everything else. This grants reliable ChatGPT access and also covers other foreign services.
The downside is higher data consumption and dependency on your proxy’s quality. If you trust your proxy’s network, give this a shot.
Of course, do remember to enable UDP forwarding.
Chat
- _index
Which Languages Are Best for Multilingual Projects
Below are 15 countries/regions—selected based on population size, economic output, and international influence—together with their language codes (shortcodes) and brief rationales, intended as a reference for multilingual translation:
| Country / Region | Shortcode | Brief Rationale |
|---|---|---|
| United States | en-US | English is the global lingua franca; the U.S. has the world’s largest GDP (population: 333 million) and is a core market for international business and technology. |
| China | zh-CN | Most populous country (1.41 billion); 2nd-largest GDP; Chinese is a UN official language; Chinese market consumption potential is enormous. |
| Japan | ja-JP | Japanese is the official language of the world’s 5th-largest economy; leading in technology and manufacturing; population: 125 million with strong purchasing power. |
| Germany | de-DE | Core of the Eurozone economy; largest GDP in Europe; German wields significant influence within the EU; population: 83.2 million with a robust industrial base. |
| France | fr-FR | French is a UN official language; France has the 7th-largest GDP globally; population: 67.81 million; widely used in Africa and international organizations. |
| India | hi-IN | Hindi is one of India’s official languages; India’s population (1.4 billion) is the world’s 2nd-largest; 6th-largest GDP and among the fastest-growing major economies. |
| Spain | es-ES | Spanish has the 2nd-largest number of native speakers worldwide (548 million); Spain’s GDP is 4th in Europe, and Spanish is common throughout Latin America. |
| Brazil | pt-BR | Portuguese is the native language of Brazil (population: 214 million); Brazil is South America’s largest economy with the 9th-largest GDP globally. |
| South Korea | ko-KR | Korean corresponds to South Korea (population: 51.74 million); 10th-largest GDP globally; powerful in technology and cultural industries such as K-pop. |
| Russia | ru-RU | Russian is a UN official language; population: 146 million; GDP ranks 11th globally; widely spoken in Central Asia and Eastern Europe. |
| Italy | it-IT | Italy’s GDP is 3rd in Europe; population: 59.06 million; strong in tourism and luxury goods; Italian is an important EU language. |
| Indonesia | id-ID | Indonesian is the official language of the world’s largest archipelagic nation (population: 276 million) and the largest GDP in Southeast Asia, presenting a high market potential. |
| Turkey | tr-TR | Turkish is spoken by 85 million people; Turkey’s strategic position bridging Europe and Asia; GDP ranks 19th globally and exerts cultural influence in the Middle East and Central Asia. |
| Netherlands | nl-NL | Dutch is spoken in the Netherlands (population: 17.5 million); GDP ranks 17th globally; leading in trade and shipping; although English penetration is high, the local market still requires the native language. |
| United Arab Emirates | ar-AE | Arabic is central to the Middle East; the UAE is a Gulf economic hub (population: 9.5 million, 88 % expatriates) with well-developed oil and finance sectors, radiating influence across the Arab world. |
Notes:
Language codes follow the ISO 639-1 (language) + ISO 3166-1 (country) standards, facilitating adaptation to localization tools.
Priority has been given to countries with populations over 100 million, GDPs in the world’s top 20, and those with notable regional influence, balancing international applicability and market value.
For particular domains (e.g., the Latin American market can add es-MX (Mexico), Southeast Asia can add vi-VN (Vietnam)), the list can be further refined as needed.
Third-party Library Pitfalls
- Third-party library pitfalls
Today we talked about a vulnerability in a recently released third-party logging library that can be exploited with minimal effort to execute remote commands. A logging library and remote command execution seem completely unrelated, yet over-engineered third-party libraries are everywhere.
The more code I read, the more I feel that a lot of open-source code is of very poor quality—regardless of how many k-stars it has. Stars represent needs, not engineering skill.
The advantage of open source is that more people contribute, allowing features to grow quickly, bugs to get fixed, and code to be reviewed. But skill levels vary wildly.
Without strong commit constraints, code quality is hard to guarantee.
The more code you add, the larger the attack surface.
Although reinventing the wheel is usually bad, product requirements are like a stroller wheel: a plastic wheel that never breaks. Attaching an airplane tire to it just adds attack surface and maintenance costs. So if all you need is a stroller wheel, don’t over-engineer.
Maintenance is expensive. Third-party libraries require dedicated processes and people to maintain them. Huawei once forked a test framework, and when we upgraded the compiler the test cases failed. Upgrading the test framework clashed with the compiler upgrade, so we burned ridiculous time making further invasive changes. As one of the people involved, I deeply felt the pain of forking third-party libraries. If the modifications were feature-worthy they could be upstreamed, but tailoring them to our own needs through intrusive customization makes future maintenance nearly impossible.
Huawei created a whole series of processes for third-party libraries—one could say the friction was enormous.
The bar is set very high: adding a library requires review by a level-18 expert and approval from a level-20 director. Only longtime, well-known libraries even have a chance.
All third-party libraries live under a thirdparty folder. A full build compares them byte-for-byte with the upstream repo; any invasive change is strictly forbidden.
Dedicated tooling tracks every library’s version, managed by outsourced staff. If a developer wants to upgrade a library, they must submit a formal request—and the director has to sign off.
Getting a director to handle something like that is hard. When a process is deliberately convoluted, its real message is “please don’t do this.”
Approach third-party libraries with skepticism—trust code written by your own team.
Design Specification Template
- Design Specification Template
Detailed Design of XXX System / Sub-system
| System Name | XXX System |
|---|---|
| Author | XXX |
| — | — |
| Submission Date | 2021-06-30 |
Revision History
| Revised Version | Change Description | Date of Change | Author |
|---|---|---|---|
| v1.0 | XXXXXXX | 2021-06-30 | XXX |
| — | — | — | — |
Technical Review Comments
| No. | Reviewer | Review Comment (Pass/Fail/Pending, comments allowed) | Review Time |
|---|---|---|---|
| 1 | XXX | Pass | 2022.1.1 |
Background
Glossary
- SIP: Session Initiation Protocol
- RTP: Real-time Transport Protocol
Design Objectives
Functional Requirements
Non-Functional Requirements (mandatory)
Environment
Related Software & Hardware (optional)
System Constraints
Estimated Data Scale (mandatory)
Existing Solutions
Design Ideas & Trade-offs
Assumptions & Dependencies / Relationships with Other Systems
System Design
Overview
Architecture Diagram & Explanation
System Flow & Explanation (optional)
Interfaces with External Systems
Global Data-Structure Descriptions
Brief Description of Module XXX1
Functionality of Module XXX1
Interfaces with Other Modules
Brief Description of Module XXX2
Functionality of Module XXX2
Interfaces with Other Modules
Threat Modeling
Upgrade Impact (mandatory)
Risk Assessment & Impact on Other Systems (optional)
Known or Foreseeable Risks
Potential Impact with Other Systems/Modules
Innovation Points (optional)
Attachments & References
Command Line Syntax Conventions
- Command line syntax conventions
References
- https://www.ibm.com/docs/en/iotdm/11.3?topic=interface-command-line-syntax
- https://learn.microsoft.com/en-us/windows-server/administration/windows-commands/command-line-syntax-key
- https://developers.google.com/style/code-syntax
- https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap12.html#tag_12_01
- https://ftpdocs.broadcom.com/cadocs/0/CA%20ARCserve%20%20Backup%20r16-CHS/Bookshelf_Files/HTML/cmndline/cl_cmd_line_syntax_char.htm
e.g.
| Notation | Description |
|---|---|
| Text without brackets or braces | Items you must type as shown. |
<Text inside angle brackets> | Placeholder for which you must supply a value. |
[Text inside square brackets] | Optional items. |
{Text inside braces} | Set of required items. You must choose one. |
Vertical bar ( | ) | Separator for mutually exclusive items. You must choose one. |
Ellipsis (…) | Items that can be repeated and used multiple times. |
Meanings of brackets in man pages
- Meanings of brackets in man pages
Meanings of brackets in man pages
In command-line help, different types of brackets generally carry the following meanings:
- Angle brackets
<>:- Angle brackets denote required arguments—values you must provide when running the command. They’re typically used to express the core syntax and parameters of a command.
- Example:
command <filename>means you must supply a filename as a required argument, e.g.,command file.txt.
- Square brackets
[]:- Square brackets indicate optional arguments—values you may or may not provide when running the command. They’re commonly used to mark optional parameters and options.
- Example:
command [option]means you can choose to provide an option, e.g.,command -vor simplycommand.
- Curly braces
{}:- Curly braces usually represent a set of choices, indicating that you must select one. These are also called “choice parameter groups.”
- Example:
command {option1 | option2 | option3}means you must pick one of the given options, e.g.,command option2.
- Parentheses
():- Parentheses are generally used to group arguments, clarifying structure and precedence in a command’s syntax.
- Example:
command (option1 | option2) filenamemeans you must choose eitheroption1oroption2and supply a filename as an argument, e.g.,command option1 file.txt.
These bracket conventions are intended to help users understand command syntax and parameter choices so they can use command-line tools correctly. When reading man pages or help text, paying close attention to the meaning and purpose of each bracket type is crucial—it prevents incorrect commands and achieves the desired results.
Huawei C++ Coding Standards
- Huawei C++ Coding Standards
C++ Language Coding Standards
Purpose
Rules are not perfect; by prohibiting features useful in specific situations, they may impact code implementation. However, the purpose of establishing rules is “to benefit the majority of developers.” If, during team collaboration, a rule is deemed unenforceable, we hope to improve it together.
Before referencing this standard, it is assumed that you already possess the corresponding basic C++ language capabilities; do not rely on this document to learn the C++ language.
- Understand the C++ language ISO standard;
- Be familiar with basic C++ language features, including those related to C++ 03/11/14/17;
- Understand the C++ standard library;
General Principles
Code must, while ensuring functional correctness, meet the feature requirements of readability, maintainability, safety, reliability, testability, efficiency, and portability.
Key Focus Areas
- Define the C++ coding style, such as naming, formatting, etc.
- C++ modular design—how to design header files, classes, interfaces, and functions.
- Best practices for C++ language features, such as constants, type casting, resource management, templates, etc.
- Modern C++ best practices, including conventions in C++11/14/17 that can improve maintainability and reliability.
- This standard is primarily applicable to C++17.
Conventions
Rule: A convention that must be followed during programming (must).
Recommendation: A convention that should be followed during programming (should).
This standard applies to common C++ standards; when no specific standard version is noted, it applies to all versions (C++03/11/14/17).
Exceptions
Regardless of ‘Rule’ or ‘Recommendation’, you must understand the reasons behind each item and strive to follow them.
However, there may be exceptions to some rules and recommendations.
If it does not violate the general principles and, after thorough consideration, there are sufficient reasons, it is acceptable to deviate from the conventions in the specification.
Exceptions break code consistency—please avoid them. Exceptions to a ‘Rule’ should be extremely rare.
In the following situations, stylistic consistency should take priority:
When modifying external open-source code or third-party code, follow the existing code style to maintain uniformity.
2 Naming
General Naming
CamelCase
Mixed case letters with words connected. Words are separated by capitalizing the first letter of each word.
Depending on whether the first letter after concatenation is capitalized, it is further divided into UpperCamelCase and lowerCamelCase.
| Type | Naming Style |
|---|---|
| Type definitions such as classes, structs, enums, and unions, as well as scope names | UpperCamelCase |
| Functions (including global, scoped, and member functions) | UpperCamelCase |
| Global variables (including global and namespace-scoped variables, class static variables), local variables, function parameters, member variables of classes, structs, and unions | lowerCamelCase |
| Macros, constants (const), enum values, goto labels | ALL CAPS, underscore separator |
Notes:
The constant in the above table refers to variables at global scope, namespace scope, or static member scope that are basic data types, enums, or string types qualified with const or constexpr; arrays and other types of variables are excluded.
The variable in the above table refers to all variables other than the constant definition above, which should all use the lowerCamelCase style.
File Naming
Rule 2.2.1 C++ implementation files end with .cpp, header files end with .h
We recommend using .h as the header suffix so header files can be directly compatible with both C and C++.
We recommend using .cpp as the implementation file suffix to clearly distinguish C++ code from C code.
Some other suffixes used in the industry:
- Header files: .hh, .hpp, .hxx
- cpp files: .cc, .cxx, .c
If your project team already uses a specific suffix, you can continue using it, but please maintain stylistic consistency.
For this document, we default to .h and .cpp as suffixes.
Rule 2.2.2 C++ file names correspond to the class name
C++ header and cpp file names should correspond to the class names in lowercase with underscores.
If a class is named DatabaseConnection, then the corresponding filenames should be:
- database_connection.h
- database_connection.cpp
File naming for structs, namespaces, enums, etc., follows a similar pattern.
Function Naming
Function names use the UpperCamelCase style, usually a verb or verb-object structure.
class List {
public:
void AddElement(const Element& element);
Element GetElement(const unsigned int index) const;
bool IsEmpty() const;
};
namespace Utils {
void DeleteUser();
}
Type Naming
Type names use the UpperCamelCase style.
All type names—classes, structs, unions, type aliases (typedef), and enums—use the same convention, e.g.:
// classes, structs and unions
class UrlTable { ...
class UrlTableTester { ...
struct UrlTableProperties { ...
union Packet { ...
// typedefs
typedef std::map<std::string, UrlTableProperties*> PropertiesMap;
// enums
enum UrlTableErrors { ...
For namespaces, UpperCamelCase is recommended:
// namespace
namespace OsUtils {
namespace FileUtils {
}
}
Recommendation 2.4.1 Avoid misusing typedef or #define to alias basic types
Do not redefine basic data types with typedef/#define unless there is a clear necessity.
Prefer using basic types from the <cstdint> header:
| Signed Type | Unsigned Type | Description |
|---|---|---|
| int8_t | uint8_t | Exactly 8-bit signed/unsigned integer |
| int16_t | uint16_t | Exactly 16-bit signed/unsigned integer |
| int32_t | uint32_t | Exactly 32-bit signed/unsigned integer |
| int64_t | uint64_t | Exactly 64-bit signed/unsigned integer |
| intptr_t | uintptr_t | Signed/unsigned integer to hold a pointer |
Variable Naming
General variables use lowerCamelCase, covering global variables, function parameters, local variables, and member variables.
std::string tableName; // Good: recommended
std::string tablename; // Bad: prohibited
std::string path; // Good: single-word lowercase per lowerCamelCase
Rule 2.5.1 Global variables must have a ‘g_’ prefix; static variables need no special prefix
Global variables should be used sparingly; adding the prefix visually reminds developers to use them carefully.
- Static global variables share the same naming as global variables.
- Function-local static variables share normal local variable naming.
- Class static member variables share normal member variable naming.
int g_activeConnectCount;
void Func()
{
static int packetCount = 0;
...
}
Rule 2.5.2 Class member variables are named in lowerCamelCase followed by a trailing underscore
class Foo {
private:
std::string fileName_; // trailing _ suffix, similar to K&R style
};
For struct/union member variables, use lowerCamelCase without suffix, consistent with local variables.
Macro, Constant, and Enum Naming
Macros and enum values use ALL CAPS, underscore-connected format.
Global-scope or named/anonymous-namespace const constants, as well as class static member constants, use ALL CAPS, underscore-connected; function-local const constants and ordinary const member variables use lowerCamelCase.
#define MAX(a, b) (((a) < (b)) ? (b) : (a)) // macro naming example only—macro not recommended for such a feature
enum TintColor { // enum type name in UpperCamelCase, values in ALL CAPS, underscore-connected
RED,
DARK_RED,
GREEN,
LIGHT_GREEN
};
int Func(...)
{
const unsigned int bufferSize = 100; // local constant
char *p = new char[bufferSize];
...
}
namespace Utils {
const unsigned int DEFAULT_FILE_SIZE_KB = 200; // global constant
}
3 Format
Line Length
Rule 3.1.1 Do not exceed 120 characters per line
We recommend keeping each line under 120 characters. If 120 characters are exceeded, choose a reasonable wrapping method.
Exceptions:
- Lines containing commands or URLs in comments may remain on one line for copy/paste / grep convenience, even above 120 chars.
- #include statements with long paths may exceed 120 chars but should be avoided when possible.
- Preprocessor error messages may span one line for readability, even above 120 chars.
#ifndef XXX_YYY_ZZZ
#error Header aaaa/bbbb/cccc/abc.h must only be included after xxxx/yyyy/zzzz/xyz.h, because xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
#endif
Indentation
Rule 3.2.1 Use spaces for indentation—4 spaces per level
Only use spaces for indentation (4 spaces per level). Do not use tab characters.
Almost all modern IDEs can be configured to automatically expand tabs to 4 spaces—please configure yours accordingly.
Braces
Rule 3.3.1 Use K&R indentation style
K&R Style
For functions (excluding lambda expressions), place the left brace on a new line at the beginning of the line, alone; for other cases, the left brace should follow statements and stay at the end of the line.
Right braces are always on their own line, unless additional parts of the same statement follow—e.g., while in do-while, else/else-if of an if-statement, comma, or semicolon.
Examples:
struct MyType { // brace follows statement with one preceding space
...
};
int Foo(int a)
{ // function left brace on a new line, alone
if (...) {
...
} else {
...
}
}
Reason for recommending this style:
- Code is more compact.
- Continuation improves reading rhythm compared to new-line placement.
- Aligns with later language conventions and industry mainstream practice.
- Modern IDEs provide alignment aids so the end-of-line brace does not hinder scoping comprehension.
For empty function bodies, the braces may be placed on the same line:
class MyClass {
public:
MyClass() : value_(0) {}
private:
int value_;
};
Function Declarations and Definitions
Rule 3.4.1 Both return type and function name must be on the same line; break and align parameters reasonably when line limit is exceeded
When declaring or defining functions, the return type and function name must appear on the same line; if permitted by the column limit, place parameters on the same line as well—otherwise break parameters onto the next line with proper alignment.
The left parenthesis always stays on the same line as the function name; placing it on its own line is prohibited. The right parenthesis always follows the last parameter.
Examples:
ReturnType FunctionName(ArgType paramName1, ArgType paramName2) // Good: all on one line
{
...
}
ReturnType VeryVeryVeryLongFunctionName(ArgType paramName1, // line limit exceeded, break
ArgType paramName2, // Good: align with previous
ArgType paramName3)
{
...
}
ReturnType LongFunctionName(ArgType paramName1, ArgType paramName2, // line limit exceeded
ArgType paramName3, ArgType paramName4, ArgType paramName5) // Good: 4-space indent after break
{
...
}
ReturnType ReallyReallyReallyReallyLongFunctionName( // will not fit first parameter, break immediately
ArgType paramName1, ArgType paramName2, ArgType paramName3) // Good: 4-space indent after break
{
...
}
Function Calls
Rule 3.5.1 Keep function argument lists on one line. If line limit is exceeded, align parameters correctly when wrapping
Function calls should have their parameter list on one line—if exceeding the line length, break and align parameters accordingly.
Left parenthesis always follows the function name; right parenthesis always follows the last parameter.
Examples:
ReturnType result = FunctionName(paramName1, paramName2); // Good: single line
ReturnType result = FunctionName(paramName1,
paramName2, // Good: aligned with param above
paramName3);
ReturnType result = FunctionName(paramName1, paramName2,
paramName3, paramName4, paramName5); // Good: 4-space indent on break
ReturnType result = VeryVeryVeryLongFunctionName( // cannot fit first param, break immediately
paramName1, paramName2, paramName3); // 4-space indent after break
If parameters are intrinsically related, grouping them for readability may take precedence over strict formatting.
// Good: each line represents a group of related parameters
int result = DealWithStructureLikeParams(left.x, left.y, // group 1
right.x, right.y); // group 2
if Statements
Rule 3.6.1 if statements must use braces
We require braces for all if statements—even for single-line conditions.
Rationale:
- Code logic is intuitive and readable.
- Adding new code to an existing conditional is less error-prone.
- Braces protect against macro misbehavior when using functional macros (in case the macro omitted braces).
if (objectIsNotExist) { // Good: braces for single-line condition
return CreateNewObject();
}
Rule 3.6.2 Prohibit writing if/else/else if on the same line
Branches in conditional statements must appear on separate lines.
Correct:
if (someConditions) {
DoSomething();
...
} else { // Good: else on new line
...
}
Incorrect:
if (someConditions) { ... } else { ... } // Bad: else same line as if
Loops
Rule 3.7.1 Loop statements must use braces
Similar to conditions, we require braces for all for/while loops—even if the body is empty or contains only one statement.
for (int i = 0; i < someRange; i++) { // Good: braces used
DoSomething();
}
while (condition) { } // Good: empty body with braces
while (condition) {
continue; // Good: continue indicates empty logic, still braces
}
Bad examples:
for (int i = 0; i < someRange; i++)
DoSomething(); // Bad: missing braces
while (condition); // Bad: semicolon appears part of loop, confusing
switch Statements
Rule 3.8.1 Indent case/default within switch bodies one additional level
Indentation for switch statements:
switch (var) {
case 0: // Good: indented
DoSomething1(); // Good: indented
break;
case 1: { // Good: brace indentation if needed
DoSomething2();
break;
}
default:
break;
}
Bad:
switch (var) {
case 0: // Bad: case not indented
DoSomething();
break;
default: // Bad: default not indented
break;
}
Expressions
Recommendation 3.9.1 Consistently break long expressions at operators, operators stranded at EOL
When an expression is too long for one line, break at an appropriate operator. Place the operator at the end-of-line, indicating ‘to be continued’.
Example:
// Assume first line exceeds limit
if ((currentValue > threshold) && // Good: logical operator at EOL
someCondition) {
DoSomething();
...
}
int result = reallyReallyLongVariableName1 + // Good
reallyReallyLongVariableName2;
After wrapping, either align appropriately or indent subsequent lines by 4 spaces.
int sum = longVariableName1 + longVariableName2 + longVariableName3 +
longVariableName4 + longVariableName5 + longVariableName6; // Good: 4-space indent
int sum = longVariableName1 + longVariableName2 + longVariableName3 +
longVariableName4 + longVariableName5 + longVariableName6; // Good: aligned
Variable Assignment
Rule 3.10.1 Multiple variable declarations and initializations are forbidden on the same line
One variable initialization per line improves readability and comprehension.
int maxCount = 10;
bool isCompleted = false;
Bad examples:
int maxCount = 10; bool isCompleted = false; // Bad: multiple initializations must span separate lines
int x, y = 0; // Bad: multiple declarations must be on separate lines
int pointX;
int pointY;
...
pointX = 1; pointY = 2; // Bad: multiple assignments placed on same line
Exception: for loop headers, if-with-initializer (C++17), structured binding statements (C++17), etc., may declare and initialize multiple variables; forcing separation would hinder scope correctness and clarity.
Initialization
Includes initialization for structs, unions, and arrays.
Rule 3.11.1 Indent initialization lists when wrapping; align elements properly
When breaking struct/array initializers, each continuation is indented 4 spaces. Choose break and alignment points for readability.
const int rank[] = {
16, 16, 16, 16, 32, 32, 32, 32,
64, 64, 64, 64, 32, 32, 32, 32
};
Pointers and References
Recommendation 3.12.1 Place the pointer star ‘*’ adjacent to the variable or type—never add spaces on both sides or omit both
Pointer naming: align ‘*’ to either left (type) or right (variable) but never leave/pad both sides.
int* p = nullptr; // Good
int *p = nullptr; // Good
int*p = nullptr; // Bad
int * p = nullptr; // Bad
Exception when const is involved—’*’ cannot trail the variable, so avoid trailing the type:
const char * const VERSION = "V100";
Recommendation 3.12.2 Place the reference operator ‘&’ adjacent to the variable or type—never pad both sides nor omit both
Reference naming: & aligned either left (type) or right (variable); never pad both sides or omit spacing.
int i = 8;
int& p = i; // Good
int &p = i; // Good
int*& rp = pi; // Good: reference to pointer; *& together after type
int *&rp = pi; // Good: reference to pointer; *& together after variable
int* &rp = pi; // Good: pointer followed by reference—* with type, & with variable
int & p = i; // Bad
int&reeeenamespace= i; // Bad—illustrates missing space or doubled up spacing issues
Preprocessor Directives
Rule 3.13.1 Place preprocessing ‘#’ at the start of the line; nested preprocessor statements may indent ‘#’ accordingly
Preprocessing directives’ ‘#’ must be placed at the beginning of the line—even if inside function bodies.
Rule 3.13.2 Avoid macros except where necessary
Macros ignore scope, type systems, and many rules and are prone to error. Prefer non-macro approaches, and if macros must be used, ensure unique macro names.
In C++, many macro use cases can be replaced:
- Use const or enum for intuitive constants
- Use namespaces to prevent name conflicts
- Use inline functions to avoid call overhead
- Use template functions for type abstraction
Macros may be used for include guards, conditional compilation, and logging where required.
Rule 3.13.3 Do not use macros to define constants
Macros are simple text substitution completed during pre-processing; typeless, unscoped, and unsafe. Debugging errors display the value, not the macro name.
Rule 3.13.4 Do not use function-like macros
Before defining a function-like macro, consider if a real function can be used. When alternatives exist, favor functions.
Disadvantages of function-like macros:
- Lack type checking vs function calls
- Macro arguments are not evaluated (behaves differently than function calls)
- No scope encapsulation
- Heavily cryptic syntax (macro operator
#and eternal parentheses) harms readability - Extensions needed (e.g., GCC statement expressions) hurt portability
- Compiler sees the macro after pre-processing; multi-line macro expansions collapse into one line, hard to debug or breakpoint
- Repeated expansion of large macros increases code size
Functions do not suffer the above negatives, although worst-case cost is reduced performance via call overhead (or due to micro-architecture optimization hassles).
To mitigate, use inline. Inline functions:
- Perform strict type checking
- Evaluate each argument once
- Expand in place with no call overhead
- May optimize better than macros
For performance-critical production code, prefer inline functions over macros.
Exception:
logging macros may need to retain FILE/LINE of the call site.
Whitespace/Blank Lines
Rule 3.14.1 Horizontal spaces should emphasize keywords and key information, avoid excessive whitespace
Horizontal spaces should highlight keywords and key info; do not pad trailing spaces. General rules:
- Add space after keywords: if, switch, case, do, while, for
- Do not pad inside parentheses both-left-and-right
- Maintain symmetry around braces
- No space after unary operators (& * + - ~ !)
- Add spaces around binary operators (= + - < > * / % | & ^ <= >= == !=)
- Add spaces around ternary operators ( ? : )
- No space between pre/post inc/dec (++, –) and variable
- No space around struct member access (., ->)
- No space before comma, but space after
- No space between <> and type names as in templates or casts
- No space around scope operator ::
- Colon (:) spaced according to context when needed
Typical cases:
void Foo(int b) { // Good: space before left brace
int i = 0; // Good: spaces around =; no space before semicolon
int buf[BUF_SIZE] = {0}; // Good: no space after {
Function definition/call examples:
int result = Foo(arg1,arg2);
// ^ Bad: comma needs trailing space
int result = Foo( arg1, arg2 );
// ^ ^ Bad: no space after ( before args; none before )
Pointer/address examples:
x = *p; // Good: no space between * and p
p = &x; // Good: no space between & and x
x = r.y; // Good: no space around .
x = r->y; // Good: no space around ->
Operators:
x = 0; // Good: spaces around =
x = -5; // Good: no space between - and 5
++x; // Good: no space between ++ and x
x--;
if (x && !y) // Good: spaces around &&, none between ! and y
v = w * x + y / z; // Good: Binary operators are surrounded by spaces.
v = w * (x + z); // Good: Expressions inside parentheses are not padded with spaces.
int a = (x < y) ? x : y; // Good: Ternary operators require spaces before ? and :.
Loops and conditional statements:
if (condition) { // Good: A space after if, none inside the parentheses
...
} else { // Good: A space after else
...
}
while (condition) {} // Good: Same rules as if
for (int i = 0; i < someRange; ++i) { // Good: Space after for, after each semicolon
...
}
switch (condition) { // Good: One space between switch and (
case 0: // Good: No space between case label and colon
...
break;
...
default:
...
break;
}
Templates and casts
// Angle brackets (< and >) are never preceded by spaces, nor followed directly by spaces.
vector<string> x;
y = static_cast<char*>(x);
// One space between a type and * is acceptable; keep it consistent.
vector<char *> x;
Scope resolution operator
std::cout; // Good: No spaces around ::
int MyClass::GetValue() const {} // Good: No spaces around ::
Colons
// When spaces are required
// Good: Space before colon with class derivation
class Sub : public Base {
};
// Constructor initializer list needs spaces
MyClass::MyClass(int var) : someVar_(var)
{
DoSomething();
}
// Bit field width also gets a space
struct XX {
char a : 4;
char b : 5;
char c : 4;
};
// When spaces are NOT required
// Good: No space after public:, private:, etc.
class MyClass {
public:
MyClass(int var);
private:
int someVar_;
};
// No space after case or default in switch statements
switch (value)
{
case 1:
DoSomething();
break;
default:
break;
}
Note: Configure your IDE to strip trailing whitespace.
Advice 3.14.1 Arrange blank lines to keep code compact
Avoid needless blank lines to display more code on screen and improve readability. Observe these guidelines:
- Insert blank lines based on logical sections, not on automatic habits.
- Do not use consecutive blank lines inside functions, type definitions, macros, or initializer lists.
- Never use three or more consecutive blank lines.
- Do not leave blank lines right after a brace that opens a block or right before the closing brace; the only exception is within namespace scopes.
int Foo()
{
...
}
int Bar() // Bad: more than two consecutive blank lines.
{
...
}
if (...) {
// Bad: blank line immediately after opening brace
...
// Bad: blank line immediately before closing brace
}
int Foo(...)
{
// Bad: blank line at start of function body
...
}
Classes
Rule 3.15.1 Order class access specifiers as public:, protected:, private: at the same indentation level as class
class MyClass : public BaseClass {
public: // Note: no extra indentation
MyClass(); // standard 4-space indent
explicit MyClass(int var);
~MyClass() {}
void SomeFunction();
void SomeFunctionThatDoesNothing()
{
}
void SetVar(int var) { someVar_ = var; }
int GetVar() const { return someVar_; }
private:
bool SomeInternalFunction();
int someVar_;
int someOtherVar_;
};
Within each section group similar declarations and order them roughly as follows: type aliases (typedef, using, nested structs / classes), constants, factory functions, constructors, assignment operators, destructor, other member functions, data members.
Rule 3.15.2 Constructor initializer lists should fit on one line or be indented four spaces and line-wrapped
// If everything fits on one line:
MyClass::MyClass(int var) : someVar_(var)
{
DoSomething();
}
// Otherwise, place after the colon and indent four spaces
MyClass::MyClass(int var)
: someVar_(var), someOtherVar_(var + 1) // Good: space after comma
{
DoSomething();
}
// If multiple lines are needed, align each initializer
MyClass::MyClass(int var)
: someVar_(var), // indent 4 spaces
someOtherVar_(var + 1)
{
DoSomething();
}
4 Comments
Prefer clear architecture and naming; only add comments when necessary to aid understanding.
Keep comments concise, accurate, and non-redundant.
Comments are as important as code.
When you change code, update all relevant comments—leaving old comments is destructive.
Use English for all comments.
Comment style
Both /* */ and // are acceptable.
Choose one consistent style for each comment category (file header, function header, inline, etc.).
Note: samples in this document frequently use trailing // merely for explanation—do not treat it as an endorsed style.
File header
Rule 3.1 File headers must contain a valid license notice
/*
- Copyright (c) 2020 XXX
- Licensed under the Apache License, Version 2.0 (the “License”);
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an “AS IS” BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. */
Function header comments
Rule 4.3.1 Provide headers for public functions
Callers need to know behavior, parameter ranges, return values, side effects, ownership, etc.—and the function signature alone cannot express everything.
Rule 4.3.2 Never leave noisy or empty function headers
Not every function needs a comment.
Only add a header when the signature is insufficient.
Headers appear above the declaration/definition using one of the following styles:
With //
// One-line function header
int Func1(void);
// Multi-line function header
// Second line
int Func2(void);
With /* */
/* Single-line function header */
int Func1(void);
/*
* Alternative single-line style
*/
int Func2(void);
/*
* Multi-line header
* Second line
*/
int Func3(void);
Cover: purpose, return value, performance hints, usage notes, memory ownership, re-entrancy etc.
Example:
/*
* Returns bytes actually written, -1 on failure.
* Caller owns the buffer buf.
*/
int WriteString(const char *buf, int len);
Bad:
/*
* Function name: WriteString
* Purpose: write string
* Parameters:
* Return:
*/
int WriteString(const char *buf, int len);
Problems:‐ parameters/return empty, function name redundant, unclear ownership.
Inline code comments
Rule 4.4.1 Place comments directly above or to the right of the code
Rule 4.4.2 Put one space after the comment token; right-side comments need ≥ 1 space
Above code: indent comment same as code.
Pick one consistent style.
With //
// Single-line comment
DoSomething();
// Multi-line
// comment
DoSomething();
With /* */
/* Single-line comment */
DoSomething();
/*
* Alternative multi-line comment
* second line
*/
DoSomething();
Right-of-code style: 1–4 spaces between code and token.
int foo = 100; // Right-side comment
int bar = 200; /* Right-side comment */
Aligning right-side comments is acceptable when cluster is tall:
const int A_CONST = 100; /* comments may align */
const int ANOTHER_CONST = 200; /* keep uniform gap */
If the right-side comment would exceed the line limit, move it to the previous standalone line.
Rule 4.4.3 Delete unused code, do not comment it out
Commented-out code cannot be maintained; resurrecting it later risks bugs.
When you no longer need code, remove it. Recoveries use version control.
This applies to /* */, //, #if 0, #ifdef NEVER_DEFINED, etc.
5 Headers
Responsibilities
Headers list a module’s public interface; design is reflected mostly here.
Keep implementation out of headers (inline functions are OK).
Headers should be single-minded; complexity and excessive dependencies hurt compile time.
Advice 5.1.1 Every .cpp file should have a matching .h file for the interface it provides
A .h file declares what the .cpp decides to expose.
If a .cpp publishes nothing to other TUs, it shouldn’t exist—except: program entry point, test code, or DLL edge cases.
Example:
// Foo.h
#ifndef FOO_H
#define FOO_H
class Foo {
public:
Foo();
void Fun();
private:
int value_;
};
#endif
// Foo.cpp
#include "Foo.h"
namespace { // Good: internal helper declared in .cpp, hidden by unnamed namespace or static
void Bar() {
}
}
...
void Foo::Fun()
{
Bar();
}
Header dependencies
Rule 5.2.1 Forbid circular #includes
a.h → b.h → c.h → a.h causes full rebuild on any change.
Refactor architecture to break cycles.
Rule 5.2.2 Every header must have an include guard #define
Do not use #pragma once.
Guidelines:
- Use a unique macro per file.
- No code/comments except the header license between #ifndef/#define and the matching #endif.
Example: For timer/include/timer.h:
#ifndef TIMER_INCLUDE_TIMER_H
#define TIMER_INCLUDE_TIMER_H
...
#endif
Rule 5.2.3 Forbid extern declarations of external functions/variables
Always #include the proper header instead of duplicating signatures with extern.
Inconsistencies may appear when the real signature changes; also encourages architectural decay.
Bad: // a.cpp
extern int Fun(); // Bad
void Bar()
{
int i = Fun();
...
}
// b.cpp
int Fun() { ... }
Good: // a.cpp
#include "b.h" // Good
...
// b.h
int Fun();
// b.cpp
int Fun() { ... }
Exception: testing private members, stubs, or patches may use extern when the header itself cannot be augmented.
Rule 5.2.4 Do not #include inside extern “C”
Such includes may nest extern “C” blocks, and some compilers have limited nesting.
Likewise, C/C++ inter-op headers may silently change linkage specifiers.
Example—files a.h / b.h:
// a.h
...
#ifdef __cplusplus
void Foo(int);
#define A(value) Foo(value)
#else
void A(int)
#endif
// b.h
#ifdef __cplusplus
extern "C" {
#endif
#include "a.h"
void B();
#ifdef __cplusplus
}
#endif
After preprocessing b.h in C++:
extern "C" {
void Foo(int);
void B();
}
Foo now gets C linkage although author wanted C++ linkage.
Exception: including a pure C header lacking extern "C" inside extern "C" is acceptable when non-intrusive.
Advice 5.2.1 Prefer #include over forward declarations
Forward declaration quick wins:
- Saves compile time by reducing header bloat.
- Breaks needless rebuilds on unrelated header edits.
Drawbacks:
- Hides real dependencies—changes in the header may not trigger recompilation.
- Subsequent library changes can break your declaration.
- Forward declaring std:: names is undefined by C++11.
- Many declarations are longer than a single #include.
- Refactoring code just to support forward declaration often hurts performance (pointer members) and clarity.
- It is hard to decide when it is truly safe.
Hence, prefer #include to keep dependencies explicit.
6 Scope
Namespaces
Advice 6.1.1 Use anonymous namespaces or static to hide file-local symbols
In C++03 static globals/funcs are deprecated, so unnamed namespaces are preferred.
Reasons:
- static already means too many things.
- namespace can also encapture types.
- Encourage uniform namespace usage.
- static functions cannot instantiate templates—namespaces can.
Never use anonymous namespace or static in a .h file.
// Foo.cpp
namespace {
const int MAX_COUNT = 20;
void InternalFun();
}
void Foo::Fun()
{
int i = MAX_COUNT;
InternalFun();
}
Rule 6.1.1 Never use using namespace in headers or before #includes
Doing so pollutes every translation unit that includes it.
Example:
// a.h
namespace NamespaceA {
int Fun(int);
}
// b.h
namespace NamespaceB {
int Fun(int);
}
using namespace NamespaceB; // Bad
// a.cpp
#include "a.h"
using namespace NamespaceA;
#include "b.h" // ambiguity: NamespaceA::Fun vs NamespaceB::Fun
Allowed: bringing in single symbols or aliases inside a custom module namespace in headers:
// foo.h
#include <fancy/string>
using fancy::string; // Bad in global namespace
namespace Foo {
using fancy::string; // Good
using MyVector = fancy::vector<int>; // C++11 type alias OK
}
Global and static member functions
Advice 6.2.1 Prefer namespaces for free functions; use static members only when tightly coupled to a class
Namespace usage avoids global namespace pollution. Only when a free function is intrinsically related to a specific class should it live as a static member.
Helper logic needed only by a single .cpp belongs in an anonymous namespace.
namespace MyNamespace {
int Add(int a, int b);
}
class File {
public:
static File CreateTempFile(const std::string& fileName);
};
Global and static member constants
Advice 6.3.1 Use namespaces to hold constants; use static members only when tied to a class
Namespaces guard against global namespace clutter. Only when the constant is logically owned by a specific class should it be a static member.
Implementation-only constants belong in an anonymous namespace.
namespace MyNamespace {
const int MAX_SIZE = 100;
}
class File {
public:
static const std::string SEPARATOR;
};
Global variables
Advice 6.4.1 Minimize global variables; use a singleton instead
Mutable globals create tight, invisible coupling across TUs:
int g_counter = 0;
// a.cpp
g_counter++;
// b.cpp
g_counter++;
// c.cpp
cout << g_counter << endl;
Singleton pattern (global unique object):
class Counter {
public:
static Counter& GetInstance()
{
static Counter counter;
return counter;
}
void Increase() { value_++; }
void Print() const { std::cout << value_ << std::endl; }
private:
Counter() : value_(0) {}
int value_;
};
// a.cpp
Counter::GetInstance().Increase();
// b.cpp
Counter::GetInstance().Increase();
// c.cpp
Counter::GetInstance().Print();
This keeps state shared globally but with better encapsulation.
Exception: if the variable is module-local (each DLL/so or executable instance carries its own), you cannot use a singleton.
7 Classes
Constructors, copy, move, assignment, and destructors
These special members manage object lifetime:
- Constructor:
X() - Copy constructor:
X(const X&) - Copy assignment operator:
operator=(const X&) - Move constructor:
X(X&&)available since C++11 - Move assignment operator:
operator=(X&&)available since C++11 - Destructor:
~X()
Rule 7.1.1 All member variables of a class must be explicitly initialized
Rationale: If a class has member variables, does not define any constructors, and lacks a default constructor, the compiler will implicitly generate one, but that generated constructor will not initialize the member variables, leaving the object in an indeterminate state.
Exceptions:
- If the member variable has a default constructor, explicit initialization is not required.
Example: The following code lacks a constructor, so the private data members are uninitialized:
class Message {
public:
void ProcessOutMsg()
{
//…
}
private:
unsigned int msgID_;
unsigned int msgLength_;
unsigned char* msgBuffer_;
std::string someIdentifier_;
};
Message message; // message members are not initialized
message.ProcessOutMsg(); // subsequent use is dangerous
// Therefore, providing a default constructor is necessary, as follows:
class Message {
public:
Message() : msgID_(0), msgLength_(0), msgBuffer_(nullptr)
{
}
void ProcessOutMsg()
{
// …
}
private:
unsigned int msgID_;
unsigned int msgLength_;
unsigned char* msgBuffer_;
std::string someIdentifier_; // has a default constructor, no explicit initialization needed
};
Advice 7.1.1 Prefer in-class member initialization (C++11) and constructor initializer lists
Rationale: C++11 in-class initialization makes the default member value obvious at a glance and should be preferred. If initialization depends on constructor parameters or C++11 is unavailable, prefer the initializer list. Compared with assigning inside the constructor body, the initializer list is more concise, performs better, and can initialize const members and references.
class Message {
public:
Message() : msgLength_(0) // Good: prefer initializer list
{
msgBuffer_ = nullptr; // Bad: avoid assignment in constructor body
}
private:
unsigned int msgID_{0}; // Good: use C++11 in-class initialization
unsigned int msgLength_;
unsigned char* msgBuffer_;
};
Rule 7.1.2 Declare single-argument constructors explicit to prevent implicit conversions
Rationale: A single-argument constructor not declared explicit acts as an implicit conversion function.
Example:
class Foo {
public:
explicit Foo(const string& name): name_(name)
{
}
private:
string name_;
};
void ProcessFoo(const Foo& foo){}
int main(void)
{
std::string test = "test";
ProcessFoo(test); // compile fails
return 0;
}
Compilation fails because ProcessFoo expects a Foo, but a std::string is supplied.
If explicit were removed, the std::string would implicitly convert into a temporary Foo object. Such silent conversions are confusing and may hide bugs. Hence single-argument constructors must be declared explicit.
Rule 7.1.3 Explicitly prohibit copy/move constructs/assignment when not needed
Rationale: Unless the user defines them, the compiler will generate copy constructor, copy assignment operator, move constructor and move assignment operator (move semantics are C++11+).
If the class should not support copying/moving, forbid them explicitly:
- Make the copy/move ctor or assignment operator
privateand leave it undefined:
class Foo {
private:
Foo(const Foo&);
Foo& operator=(const Foo&);
};
Use
= deletefrom C++11, see the Modern C++ section.Prefer inheriting from
NoCopyable,NoMovable; disallow macros such asDISALLOW_COPY_AND_MOVE,DISALLOW_COPY,DISALLOW_MOVE.
class Foo : public NoCopyable, public NoMovable {
};
Implementation of NoCopyable and NoMovable:
class NoCopyable {
public:
NoCopyable() = default;
NoCopyable(const NoCopyable&) = delete;
NoCopyable& operator = (NoCopyable&) = delete;
};
class NoMovable {
public:
NoMovable() = default;
NoMovable(NoMovable&&) noexcept = delete;
NoMovable& operator = (NoMovable&&) noexcept = delete;
};
Rule 7.1.4 Provide or prohibit both copy constructor and copy assignment together
Since both operations have copy semantics, allow or forbid them in pairs.
// Both provided
class Foo {
public:
...
Foo(const Foo&);
Foo& operator=(const Foo&);
...
};
// Both defaulted (C++11)
class Foo {
public:
Foo(const Foo&) = default;
Foo& operator=(const Foo&) = default;
};
// Both prohibited; in C++11 use `delete`
class Foo {
private:
Foo(const Foo&);
Foo& operator=(const Foo&);
};
Rule 7.1.5 Provide or prohibit both move constructor and move assignment together
Move semantics were added in C++11. If a class needs to support moving, both move constructor and move assignment must be present or both deleted.
// Both provided
class Foo {
public:
...
Foo(Foo&&);
Foo& operator=(Foo&&);
...
};
// Both defaulted
class Foo {
public:
Foo(Foo&&) = default;
Foo& operator=(Foo&&) = default;
};
// Both deleted
class Foo {
public:
Foo(Foo&&) = delete;
Foo& operator=(Foo&&) = delete;
};
Rule 7.1.6 Never call virtual functions in constructors or destructors
Rationale: Calling a virtual function on the object under construction/destruction prevents the intended polymorphic behavior.
In C++, a base class is only building one sub-object at a time.
Example:
class Base {
public:
Base();
virtual void Log() = 0; // Derived classes use different log files
};
Base::Base() // base constructor
{
Log(); // virtual call inside ctor
}
class Sub : public Base {
public:
virtual void Log();
};
When executing Sub sub;, Sub’s ctor runs first but calls Base() first; during Base(), the virtual call to Log binds to Base::Log, not Sub::Log. The same applies in destructors.
Rule 7.1.7 Copy/move constructs/assignment of polymorphic bases must be non-public or deleted
Assigning a derived object to a base object causes slicing: only the base part is copied/moved, breaking polymorphism.
Negative Example:
class Base {
public:
Base() = default;
virtual ~Base() = default;
...
virtual void Fun() { std::cout << "Base" << std::endl;}
};
class Derived : public Base {
...
void Fun() override { std::cout << "Derived" << std::endl; }
};
void Foo(const Base &base)
{
Base other = base; // slicing occurs
other.Fun(); // calls Base::Fun
}
Derived d;
Foo(d); // derived passed in
Declare copy/move operations delete or private so the compiler rejects such assignments.
Inheritance
Rule 7.2.1 Base class destructors must be virtual; classes not intended for inheritance should be marked final
Rationale: A base destructor must be virtual to ensure derived destructors run when the object is deleted via a base pointer.
Example: A base destructor missing virtual causes memory leaks.
class Base {
public:
virtual std::string getVersion() = 0;
~Base()
{
std::cout << "~Base" << std::endl;
}
};
class Sub : public Base {
public:
Sub() : numbers_(nullptr)
{
}
~Sub()
{
delete[] numbers_;
std::cout << "~Sub" << std::endl;
}
int Init()
{
const size_t numberCount = 100;
numbers_ = new (std::nothrow) int[numberCount];
if (numbers_ == nullptr) {
return -1;
}
...
}
std::string getVersion()
{
return std::string("hello!");
}
private:
int* numbers_;
};
int main(int argc, char* args[])
{
Base* b = new Sub();
delete b;
return 0;
}
Because Base::~Base is not virtual, only its destructor is invoked; Sub::~Sub is skipped and numbers_ leaks.
Exceptions: Marker classes like NoCopyable, NoMovable need neither virtual destructors nor final.
Rule 7.2.2 Virtual functions must not have default arguments
Rationale: In C++, virtual dispatch happens at runtime but default arguments are bound at compile time. The selected function body is from the derived class while its default parameter values come from the base, causing surprising behavior.
Example: the program emits “Base!” instead of the expected “Sub!”
class Base {
public:
virtual void Display(const std::string& text = "Base!")
{
std::cout << text << std::endl;
}
virtual ~Base(){}
};
class Sub : public Base {
public:
virtual void Display(const std::string& text = "Sub!")
{
std::cout << text << std::endl;
}
virtual ~Sub(){}
};
int main()
{
Base* base = new Sub();
Sub* sub = new Sub();
...
base->Display(); // prints: Base!
sub->Display(); // prints: Sub!
delete base;
delete sub;
return 0;
};
Rule 7.2.3 Do not override an inherited non-virtual function
Non-virtual functions are bound statically; only virtual functions provide dynamic dispatch.
Example:
class Base {
public:
void Fun();
};
class Sub : public Base {
public:
void Fun();
};
Sub* sub = new Sub();
Base* base = sub;
sub->Fun(); // calls Sub::Fun
base->Fun(); // calls Base::Fun
//...
Multiple Inheritance
Real-world use of multiple inheritance in our code base is rare because it brings several typical problems:
- The diamond inheritance issue causes data duplication and name ambiguity; C++ introduces virtual inheritance to address it.
- Even without diamond inheritance, name clashes between different bases can create ambiguity.
- When a subclass needs to extend/override methods in multiple bases, its responsibilities become unclear, leading to confusing semantics.
- Inheritance is white-box reuse: subclasses have access to parents’
protectedmembers, creating stronger coupling. Multiple inheritance compounds the coupling.
Benefits:
Multiple inheritance offers a simpler way to assemble interfaces and behaviors.
Hence multiple inheritance is allowed only in the following cases.
Advice 7.3.1 Use multiple inheritance for interface segregation and multi-role composition
If a class must implement several unrelated interfaces, inherit from separate base classes that represent those roles—similar to Scala traits.
class Role1 {};
class Role2 {};
class Role3 {};
class Object1 : public Role1, public Role2 {
// ...
};
class Object2 : public Role2, public Role3 {
// ...
};
The C++ standard library also demonstrates this pattern:
class basic_istream {};
class basic_ostream {};
class basic_iostream : public basic_istream, public basic_ostream {
};
Overloading
Overload operators only with good reason and without altering their intuitive semantics; e.g., never use ‘+’ for subtraction.
Operator overloading makes code intuitive, but also has drawbacks:
- It can mislead readers into assuming built-in efficiency and overlook potential slowdowns;
- Debugging is harder—finding a function name is easier than locating operator usage.
- Non-intuitive behaviour (e.g., ‘+’ subtracting) obfuscates code.
- Implicit conversions triggered by assignment operator overloads can hide deep bugs. Prefer functions like
Equals(),CopyFrom()instead of overloading==,=.
8 Functions
Function Design
Rule 8.1.1 Keep functions short; no more than 50 non-blank non-comment lines
A function should fit on one screen (≤ 50 lines), do one thing, and do it well.
Long functions often indicate mixed concerns, excessive complexity, or missing abstractions.
Exceptions: Algorithmic routines that are inherently cohesive and complete might exceed 50 lines.
Even if the current version works well, future changes may introduce subtle bugs. Splitting into smaller, focused functions eases readability and maintenance.
Inline Functions
Advice 8.2.1 Inline functions should be no more than 10 lines (non-blank non-comment)
Inline functions retain the usual semantics; they just expand in place. Ordinary functions incur call/return overhead; inline functions substitute the body directly.
Inlining only makes sense for very small functions (1–10 lines). For large functions the call-cost is negligible, and compilers usually fall back to normal calls.
Complex control flow (loops, switch, try-catch) normally precludes inlining.
Virtual functions and recursive functions cannot be inlined.
Function Parameters
Advice 8.3.1 Prefer references over pointers for parameters
References are safer: they cannot be null and cannot be reseated after binding; no null pointer checks required.
On legacy platforms follow existing conventions.
Use const to enforce immutability and document the intent, enhancing readability.
Exception: when passing run-time sized arrays, pointers may be used.
Advice 8.3.2 Use strong typing; avoid void*
C/C++ is strongly typed; keep the style consistent. Strong type checking allows the compiler to detect mismatches early.
Using strong types prevents defects. Watch the poorly typed FooListAddNode below:
struct FooNode {
struct List link;
int foo;
};
struct BarNode {
struct List link;
int bar;
}
void FooListAddNode(void *node) // Bad: using `void *`
{
FooNode *foo = (FooNode *)node;
ListAppend(&g_FooList, &foo->link);
}
void MakeTheList()
{
FooNode *foo = nullptr;
BarNode *bar = nullptr;
...
FooListAddNode(bar); // Wrong: meant `foo`, compiles anyway
}
- Use template functions for variant parameter types.
- Prefer polymorphic base-class pointers/ references.
Advice 8.3.3 Functions shall have no more than 5 parameters
Too many parameters increase coupling to callers and complicate testing.
If you exceed this:
- Consider splitting the function.
- Group related parameters into a single struct.
9 Additional C++ Features
Constants and Initialization
Immutable values are easier to understand, trace and analyze; default to const for any definition.
Rule 9.1.1 Do not use macros to define constants
Macros perform simple textual substitution at preprocessing time; error traces and debuggers show raw values instead of names.
Macros lack type checking and scope.
#define MAX_MSISDN_LEN 20 // bad
// use C++ const
const int MAX_MSISDN_LEN = 20; // good
// for C++11+, prefer constexpr
constexpr int MAX_MSISDN_LEN = 20;
Advice 9.1.1 Group related integer constants using enums
Enums are safer than #define or const int; the compiler validates values.
// good:
enum Week {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY
};
enum Color {
RED,
BLACK,
BLUE
};
void ColorizeCalendar(Week today, Color color);
ColorizeCalendar(BLUE, SUNDAY); // compile-time error: type mismatch
// poor:
const int SUNDAY = 0;
const int MONDAY = 1;
const int BLACK = 0;
const int BLUE = 1;
bool ColorizeCalendar(int today, int color);
ColorizeCalendar(BLUE, SUNDAY); // compiles fine
When enum values map to specific constants, assign them explicitly; otherwise omit assignments to avoid redundancy.
// good: device types per protocol S
enum DeviceType {
DEV_UNKNOWN = -1,
DEV_DSMP = 0,
DEV_ISMG = 1,
DEV_WAPPORTAL = 2
};
Internal enums used only for categorization should not have explicit values.
// good: session states
enum SessionState {
INIT,
CLOSED,
WAITING_FOR_RESPONSE
};
Avoid duplicate values; if unavoidable, qualify them:
enum RTCPType {
RTCP_SR = 200,
RTCP_MIN_TYPE = RTCP_SR,
RTCP_RR = 201,
RTCP_SDES = 202,
RTCP_BYE = 203,
RTCP_APP = 204,
RTCP_RTPFB = 205,
RTCP_PSFB = 206,
RTCP_XR = 207,
RTCP_RSI = 208,
RTCP_PUBPORTS = 209,
RTCP_MAX_TYPE = RTCP_PUBPORTS
};
Rule 9.1.2 Forbid magic numbers
“Magic numbers” are literals whose meaning is opaque or unclear.
Clarity is contextual: type = 12 is unclear, whereas monthsCount = yearsCount * 12 is understandable.
Even 0 can be cryptic, e.g., status = 0.
Solution:
Comment locally used literals, or create named const for widely used ones.
Prohibited practices:
- Names just map a macro to the literal, e.g.,
const int ZERO = 0 - Names hard-code limits, e.g.,
const int XX_TIMER_INTERVAL_300MS = 300; useXX_TIMER_INTERVAL_MS.
Rule 9.1.3 Each constant shall have a single responsibility
A constant must express only one concept; avoid reuse for unrelated purposes.
// good: for two protocols that both allow 20-digit MSISDNs
const unsigned int A_MAX_MSISDN_LEN = 20;
const unsigned int B_MAX_MSISDN_LEN = 20;
// or use distinct namespaces
namespace Namespace1 {
const unsigned int MAX_MSISDN_LEN = 20;
}
namespace Namespace2 {
const unsigned int MAX_MSISDN_LEN = 20;
}
Rule 9.1.4 Do not use memcpy_s, memset_s to initialize non-POD objects
POD (“Plain Old Data”) includes primitive types, aggregates, etc., without non-trivial default constructors, virtual functions, or base classes.
Non-POD objects (e.g., classes with virtual functions) have uncertain layouts defined by the ABI; misusing memory routines leads to undefined behavior. Even for aggregates, raw memory manipulation violates information hiding and should be avoided.
See the appendix for detailed POD specifications.
Advice 9.1.2 Declare variables at point of first use and initialize them
Using un-initialized variables is a common bug. Defining variables as late as possible and initializing immediately avoids such errors.
Declaring all variables up front leads to:
- Poor readability and maintenance: definition sites are far from usage sites.
- Variables are hard to initialize appropriately: at the beginning of a function, we often lack enough information to initialize them, so we initialize them with some empty default (e.g., zero). That is usually a waste and can also lead to errors if the variable is used before it is assigned a valid value.
Following the principle of minimizing variable scope and declaring variables as close as possible to their first use makes code easier to read and clarifies the type and initial value of every variable. In particular, initialization should be used instead of declaration followed by assignment.
// Bad: declaration and initialization are separated
string name; // default-constructed at declaration
name = "zhangsan"; // assignment operator called; definition far from declaration, harder to understand
// Good: declaration and initialization are combined, easier to understand
string name("zhangsan"); // constructor called directly
Expressions
Rule 9.2.1 Do not reference a variable again inside the same expression that increments or decrements it
C++ makes no guarantee about the order of evaluation when a variable that undergoes pre/post increment or decrement is referenced again within the same expression. Different compilers—or even different versions of the same compiler—may behave differently.
For portable code, never rely on such unspecified sequencing.
Notice that adding parentheses does not solve the problem, because this is a sequencing issue, not a precedence issue.
Example:
x = b[i] + i++; // Bad: the order of evaluating b[i] and i++ is unspecified.
Write the increment/decrement on its own line:
x = b[i] + i;
i++; // Good: on its own line
Function arguments
Func(i++, i); // Bad: cannot tell whether the increment has happened when passing the second argument
Correct:
i++; // Good: on its own line
x = Func(i, i);
Rule 9.2.2 Provide a default branch in every switch statement
In most cases, a switch statement must contain a default branch so that unlisted cases have well-defined behavior.
Exception:
If the control variable is of an enum type and all enumerators are covered by explicit case labels, a default branch is superfluous.
Modern compilers issue a warning when an enumerator in an enum is missing from the switch.
enum Color {
RED = 0,
BLUE
};
// Because the switch variable is an enum and all enumerators are covered, we can omit default
switch (color) {
case RED:
DoRedThing();
break;
case BLUE:
DoBlueThing();
...
break;
}
Suggestion 9.2.1 When writing comparisons, put the variable on the left and the constant on the right
It is unnatural to read if (MAX == v) or even harder if (MAX > v).
Write the more readable form:
if (value == MAX) {
}
if (value < MAX) {
}
One exception is range checks: if (MIN < value && value < MAX), where the left boundary is a constant.
Do not worry about accidentally typing = instead of ==; compilers and static-analysis tools will warn about if (value = MAX). Leave typos to the tools; the code must be clear to humans.
Suggestion 9.2.2 Use parentheses to clarify operator precedence
Parentheses make the intended precedence explicit, preventing bugs caused by mismatching the default precedence rules, while simultaneously improving readability. Excessive parentheses, however, can clutter the code. Some guidance:
- If an expression contains two or more different binary operators, parenthesize it.
x = a + b + c; /* same operators, parentheses optional */
x = Foo(a + b, c); /* comma operator, no need for extra parentheses */
x = 1 << (2 + 3); /* different operators, parentheses needed */
x = a + (b / 5); /* different operators, parentheses needed */
x = (a == b) ? a : (a – b); /* different operators, parentheses needed */
Type Casting
Never customize behavior through type branching: that style is error-prone and a clear sign of writing C code in C++. It is inflexible; when a new type is added, every branch must be changed—and the compiler will not remind you. Use templates or virtual functions to let each type determine its behavior, rather than letting the calling code do it.
Avoid type casting; design types that clearly express what kind of object they represent without the need for casting. When designing a numeric type, decide:
- signed or unsigned
- float vs double
- int8, int16, int32, or int64
Inevitably, some casts remain; C++ is close to the machine and talks to APIs whose type designs are not ideal. Still, keep them to a minimum.
Exception: if a function’s return value is intentionally ignored, first reconsider the design. If ignoring it is really appropriate, cast it to (void).
Rule 9.3.1 Use the C++-style casts; never C-style casts
C++ casts are more specific, more readable, and safer. The C++ casts are:
For type conversions
dynamic_cast— down-cast in an inheritance hierarchy and provides run-time type checking. Avoid it by improving base/derived design instead.static_cast— like C-style but safer. Used for value conversions or up-casting, and resolving multiple-inheritance ambiguities. Prefer brace-init for pure arithmetic.reinterpret_cast— reinterprets one type as another. Undefined behaviour potential, use sparingly.const_cast— removes const or volatile. Suppresses immutability, leading to UB if misused.
Numeric conversions (C++11 onwards)
Use brace-init for converting between numeric types without loss.
double d{ someFloat };
int64_t i{ someInt32 };
Suggestion 9.3.1 Avoid dynamic_cast
dynamic_castdepends on RTTI, letting programs discover an object’s concrete type at run time.- Its necessity usually signals a flaw in the class hierarchy; prefer redesigning classes instead.
Suggestion 9.3.2 Avoid reinterpret_cast
reinterpret_cast performs low-level re-interpretations of memory layouts and is inherently unsafe. Avoid crossing unrelated type boundaries.
Suggestion 9.3.3 Avoid const_cast
const_cast strips the const and volatile qualifiers off an object. Modifying a formerly const variable via such a cast yields Undefined Behaviour.
// Bad
const int i = 1024;
int* p = const_cast<int*>(&i);
*p = 2048; // Undefined Behaviour
// Bad
class Foo {
public:
Foo() : i(3) {}
void Fun(int v) { i = v; }
private:
int i;
};
int main() {
const Foo f;
Foo* p = const_cast<Foo*>(&f);
p->Fun(8); // Undefined Behaviour
}
Resource Acquisition and Release
Rule 9.4.1 Use delete for single objects and delete[] for arrays
- single object:
newallocates and constructs exactly one object ⇒ dispose withdelete. - array:
new[]allocates space for (n) objects and constructs them ⇒ dispose withdelete[].
Mismatching new/new[] with the wrong form of delete yields UB.
Wrong:
const int MAX_ARRAY_SIZE = 100;
int* numberArray = new int[MAX_ARRAY_SIZE];
...
delete numberArray; // ← wrong
Right:
const int MAX_ARRAY_SIZE = 100;
int* numberArray = new int[MAX_ARRAY_SIZE];
...
delete[] numberArray;
Suggestion 9.4.1 Use RAII to track dynamic resources
RAII = Resource Acquisition Is Initialization. Acquire a resource in a constructor; the destructor releases it. Benefits:
- No manual cleanup.
- The resource remains valid for the scope’s lifetime.
Example: mutex guard
class LockGuard {
public:
LockGuard(const LockType& lock) : lock_(lock) { lock_.Acquire(); }
~LockGuard() { lock_.Release(); }
private:
LockType lock_;
};
bool Update() {
LockGuard g(mutex);
...
}
Standard Library
STL usage varies between products; basic rules below.
Rule 9.5.1 Never store the pointer returned by std::string::c_str()
string::c_str() is not guaranteed to point at stable memory. A specific implementation may return memory that is released soon after the call. Therefore, call string::c_str() at point of use; do not store the pointer.
Example:
void Fun1() {
std::string name = "demo";
const char* text = name.c_str(); // still valid here
name = "test"; // may invalidate text
...
}
Exception: in extremely performance-critical code it is acceptable to store the pointer, provided the std::string is guaranteed to outlive the pointer and remain unmodified while the pointer is used.
Suggestion 9.5.1 Prefer std::string over char*
Advantages:
- no manual null-termination
- built-in operators (
+,=,==) - automatic memory management
Be aware: some legacy STL implementations use Copy-On-Write (COW) strings. COW is not thread-safe and can cause crashes. Passing COW strings across DLL boundaries can leave dangling references. Choose a modern, non-COW STL when possible.
Exception: APIs that require 'char*' get it from std::string::c_str(). Stack buffers should be plain char arrays, not std::string or std::vector<char>.
Rule 9.5.2 Do not use auto_ptr
std::auto_ptr performs implicit (and surprising) ownership transfer:
auto_ptr<T> p1(new T);
auto_ptr<T> p2 = p1; // p1 becomes nullptr
Therefore it is forbidden.
Use std::unique_ptr for exclusive ownership, std::shared_ptr for shared ownership.
Suggestion 9.5.2 Prefer canonical C++ headers
Use <cstdlib> instead of <stdlib.h>, etc.
const Qualifier
Add const to variables and parameters whose values must not change. Mark member functions const if they do not modify the observable state.
Rule 9.6.1 Use const for pointer/reference parameters that are read-only
Write:
void PrintFoo(const Foo& foo);
instead of Foo&.
Rule 9.6.2 Mark member functions const when they do not modify the object
Accessors should always be const.
class Foo {
public:
int PrintValue() const;
int GetValue() const;
private:
int value_;
};
Suggestion 9.6.1 Declare member variables const when they never change after initialization
class Foo {
public:
Foo(int length) : dataLength_(length) {}
private:
const int dataLength_;
};
Exceptions
Suggestion 9.7.1 Mark functions that never throw as noexcept (C++11)
Benefits:
- Enables better code generation.
- Standard containers only use move-construction when a move operator is noexcept. Without
noexceptthey fall back to (slower) copy-construction.
Example:
extern "C" double sqrt(double) noexcept;
std::vector<int> Compute(const std::vector<int>& v) noexcept {
...
}
Destructor, default constructors, swap, and move operations must never throw.
Templates & Generic Programming
Rule 9.8.1 Prohibit generic programming in the OpenHarmony project
Generic programming, templates, and OOP are driven by entirely different ideas and techniques. OpenHarmony is mainly based on OOP.
Avoid templates because:
- Inexperienced developers tend to produce bloated, confusing code.
- Template code is hard to read and debug.
- Error messages are notoriously cryptic.
- Templates may generate excessive code size.
- Refactoring template code is difficult because its instantiations are spread across the codebase.
OpenHarmony forbids template programming in most modules.
Exception: STL adaptation layers may still use templates.
Macros
Avoid complex macros. Instead:
- Use
constor enums for constants. - Replace macro functions with inline or template functions.
// Bad
#define SQUARE(a, b) ((a) * (b))
// Prefer
template<typename T>
T Square(T a, T b) { return a * b; }
10 Modern C++ Features
ISO standardized C++11 in 2011 and C++17 in March 2017. These standards add countless improvements. This chapter highlights best practices for using them effectively.
Brevity & Safety
Suggestion 10.1.1 Use auto judiciously
- Eliminates long type names, guarantees initialization.
- Deduction rules are subtle—understand them.
- Prefer explicit types if clarity improves. Use
autoonly for local variables.
Examples:
auto iter = m.find(val);
auto p = new Foo;
int x; // uninitialized
auto x; // compile-time error—uninitialized
Beware deduced types:
std::vector<std::string> v;
auto s1 = v[0]; // std::string, makes a copy
Rule 10.1.1 Override virtual functions with override or final
They ensure correctness: the compiler rejects overrides whose signatures do not match the base declaration.
class Base {
virtual void Foo();
};
class Derived : public Base {
void Foo() override; // OK
void Foo() const override; // Error: signature differs
};
Rule 10.1.2 Delete functions with the delete keyword
Clearer and broader than making members private and undefined.
Foo& operator=(const Foo&) = delete;
Rule 10.1.3 Prefer nullptr to NULL or 0
nullptr has its own type (std::nullptr_t) and unambiguous behaviour; 0/NULL cannot.
Or, when a null pointer is required, directly using 0 can introduce another problem: the code becomes unclear—especially when auto is used:
auto result = Find(id);
if (result == 0) { // Does Find() return a pointer or an integer?
// do something
}
Literally, 0 is of type int (0L is long), so neither NULL nor 0 is of a pointer type.
When a function is overloaded for both pointer and integer types, passing NULL or 0 will invoke the integer overload:
void F(int);
void F(int*);
F(0); // Calls F(int), not F(int*)
F(NULL); // Calls F(int), not F(int*)
Moreover, sizeof(NULL) == sizeof(void*) is not necessarily true, which is another potential pitfall.
Summary: directly using 0 or 0L makes the code unclear and type-unsafe; using NULL is no better than 0 because it is also type-unsafe. All of them involve potential risks.
The advantage of nullptr is not just being a literal representation of the null pointer that clarifies the code, but also that it is definitively not an integer type.
nullptr is of type std::nullptr_t, and std::nullptr_t can be implicitly converted to any raw pointer type, so nullptr can act as the null pointer for any type.
void F(int);
void F(int*);
F(nullptr); // Calls F(int*)
auto result = Find(id);
if (result == nullptr) { // Find() returns a pointer
// do something
}
Rule 10.1.4: Prefer using over typedef
Prior to C++11, you could define type aliases with typedef; nobody wants to repeatedly type std::map<uint32_t, std::vector<int>>.
typedef std::map<uint32_t, std::vector<int>> SomeType;
An alias is essentially an encapsulation of the real type. This encapsulation makes code clearer and prevents shotgun surgery when the underlying type changes.
Since C++11, using provides alias declarations:
using SomeType = std::map<uint32_t, std::vector<int>>;
Compare their syntaxes:
typedef Type Alias; // Is Type first or Alias first?
using Alias = Type; // Reads like assignment—intuitive and error-proof
If that alone isn’t enough to adopt using, look at alias templates:
// Alias template definition—one line
template<class T>
using MyAllocatorVector = std::vector<T, MyAllocator<T>>;
MyAllocatorVector<int> data; // Using the alias
template<class T>
class MyClass {
private:
MyAllocatorVector<int> data_; // Alias usable inside a template
};
typedef does not support template parameters in aliases; workarounds are required:
// Need to wrap typedef in a template struct
template<class T>
struct MyAllocatorVector {
typedef std::vector<T, MyAllocator<T>> type;
};
MyAllocatorVector<int>::type data; // Using typedef—must append ::type
template<class T>
class MyClass {
private:
typename MyAllocatorVector<int>::type data_; // Need typename too
};
Rule 10.1.5: Do not apply std::move to const objects
Semantically, std::move is about moving an object. A const object cannot be modified and is therefore immovable, so applying std::move confuses readers.
Functionally, std::move yields an rvalue reference; for const objects this becomes const&&. Very few types provide move constructors or move-assignment operators taking const&&, so the operation usually degrades to a copy, harming performance.
Bad:
std::string g_string;
std::vector<std::string> g_stringList;
void func()
{
const std::string myString = "String content";
g_string = std::move(myString); // Bad: copies, does not move
const std::string anotherString = "Another string content";
g_stringList.push_back(std::move(anotherString)); // Bad: also copies
}
Smart Pointers
Rule 10.2.1: Prefer raw pointers for singletons, data members, etc., whose ownership is never shared
Rationale
Smart pointers prevent leaks by automatically releasing resources but add overhead—code bloat, extra construction/destruction cost, increased memory footprint, etc.
For objects whose ownership is never transferred (singletons, data members), simply deleting them in the destructor is sufficient; avoid the extra smart-pointer overhead.
Example
class Foo;
class Base {
public:
Base() {}
virtual ~Base()
{
delete foo_;
}
private:
Foo* foo_ = nullptr;
};
Exceptions
- When returning newly created objects that need custom deleters, smart pointers are acceptable.
class User;
class Foo {
public:
std::unique_ptr<User, void(User *)> CreateUniqueUser()
{
sptr<User> ipcUser = iface_cast<User>(remoter);
return std::unique_ptr<User, void(User *)>(::new User(ipcUser), [](User *user) {
user->Close();
::delete user;
});
}
std::shared_ptr<User> CreateSharedUser()
{
sptr<User> ipcUser = iface_cast<User>(remoter);
return std::shared_ptr<User>(ipcUser.GetRefPtr(), [ipcUser](User *user) mutable {
ipcUser = nullptr;
});
}
};
- Use
shared_ptrwhen returning a newly created object that can have multiple owners.
Rule 10.2.2: Use std::make_unique, not new, to create a unique_ptr
Rationale
make_uniqueis more concise.- It provides exception safety in complex expressions.
Example
// Bad: type appears twice—possible inconsistency
std::unique_ptr<MyClass> ptr(new MyClass(0, 1));
// Good: type appears only once
auto ptr = std::make_unique<MyClass>(0, 1);
Repetition can cause subtle bugs:
// Compiles, but mismatched new[] and delete
std::unique_ptr<uint8_t> ptr(new uint8_t[10]);
std::unique_ptr<uint8_t[]> ptr(new uint8_t);
// Not exception-safe: evaluation order may be
// 1. allocate Foo
// 2. construct Foo
// 3. call Bar
// 4. construct unique_ptr<Foo>
// If Bar throws, Foo leaks.
F(unique_ptr<Foo>(new Foo()), Bar());
// Exception-safe: no interleaving
F(make_unique<Foo>(), Bar());
Exceptionstd::make_unique does not support custom deleters.
Fall back to new only when a custom deleter is required.
Rule 10.2.4: Use std::make_shared, not new, to create a shared_ptr
Rationale
Besides the same consistency benefits as make_unique, make_shared offers performance gains.
A shared_ptr manages two entities:
- Control block (ref-count, deleter, etc.)
- The owned object
make_shared allocates one heap block for both, whereasstd::shared_ptr<MyClass>(new MyClass) performs two allocations: one for MyClass and one for the control block, adding overhead.
Exception
Like make_unique, make_shared cannot accept a custom deleter.
Lambda Expressions
Advice 10.3.1: Prefer lambda expressions when a function cannot express what you need (capture locals, local function)
Rationale
Functions cannot capture locals nor be declared in local scope. When you need such features, use lambda rather than hand-written functors.
Conversely, lambdas and functors can’t be overloaded; overloadable cases favor functions.
When both lambdas and functions work, prefer functions—always reach for the simplest tool.
Example
// Overloads for int and string—natural to choose
void F(int);
void F(const string&);
// Needed: capture locals or appear inline
vector<Work> v = LotsOfWork();
for (int taskNum = 0; taskNum < max; ++taskNum) {
pool.Run([=, &v] {...});
}
pool.Join();
Rule 10.3.1: Return or store lambdas outside local scope only by value capture; never by reference
Rationale
A non-local lambda (returned, stored on heap, passed to another thread) must not hold dangling references; avoid capture by reference.
Example
// Bad
void Foo()
{
int local = 42;
// Capture by reference; `local` dangles after return
threadPool.QueueWork([&]{ Process(local); });
}
// Good
void Foo()
{
int local = 42;
// Capture by value
threadPool.QueueWork([=]{ Process(local); });
}
Advice 10.3.2: If you capture this, write all other captures explicitly
Rationale
Inside a member function [=] looks like capture-by-copy, but it implicitly captures this by copy, yielding handles to every data member (i.e., reference semantics in disguise). When you really want that, write it explicitly.
Example
class MyClass {
public:
void Foo()
{
int i = 0;
auto Lambda = [=]() { Use(i, data_); }; // Bad: not a true copy of data_
data_ = 42;
Lambda(); // Uses 42
data_ = 43;
Lambda(); // Uses 43; shows reference semantics
auto Lambda2 = [i, this]() { Use(i, data_); }; // Good: explicit, no surprises
}
private:
int data_ = 0;
};
Advice 10.3.3: Avoid default capture modes
Rationale
Lambdas support default-by-reference (&) and default-by-value (=).
Default-by-reference silently binds every local variable; easy to create dangling refs.
Default-by-value implicitly captures this and hides which variables are actually used; readers may mistakenly believe static variables are copied too.
Therefore always list the captures explicitly.
Bad
auto func()
{
int addend = 5;
static int baseValue = 3;
return [=]() { // only copies addend
++baseValue; // modifies global
return baseValue + addend;
};
}
Good
auto func()
{
int addend = 5;
static int baseValue = 3;
return [addend, baseValue = baseValue]() mutable { // C++14 capture-init
++baseValue; // modifies local copy
return baseValue + addend;
};
}
Reference: Effective Modern C++, Item 31: Avoid default capture modes.
Interfaces
Advice 10.4.1: In interfaces not concerned with ownership, pass T* or T&, not smart pointers
Rationale
- Smart pointers transfer or share ownership only when needed.
- Requiring smart pointers forces callers to use them (e.g., impossible to pass
this). - Passing shared-ownership smart pointers incurs runtime overhead.
Example
// Accepts any int*
void F(int*);
// Accepts only when ownership is to be transferred
void G(unique_ptr<int>);
// Accepts only when ownership is to be shared
void G(shared_ptr<int>);
// Ownership unchanged, but caller must hold a unique_ptr
void H(const unique_ptr<int>&);
// Accepts any int
void H(int&);
// Bad
void F(shared_ptr<Widget>& w)
{
// ...
Use(*w); // lifetime not relevant
// ...
}
linux
- _index
linux tour
linux tour
[内核模块开发]
Troubleshooting
windows
Windows SSH Remote Login
Enabling SSH remote access on Windows typically requires Windows’ built-in OpenSSH feature. Below are step-by-step instructions:
Check and Install OpenSSH
Check whether OpenSSH is already installed:
- Open Settings > Apps > Apps & features > Manage optional features.
- Look for OpenSSH Server in the list. If found, it is already installed.
Install OpenSSH:
- If OpenSSH Server is not listed, click Add a feature, locate OpenSSH Server in the list, click it, then click Install.
Start and Configure the OpenSSH Service
Start the OpenSSH service:
- After installation, open Command Prompt (run as administrator).
- Type
net start sshdto start the OpenSSH service. To make it start automatically at boot, runsc config sshd start= auto.
Configure the firewall:
- Ensure the Windows firewall allows SSH connections. Go to Control Panel > System and Security > Windows Defender Firewall > Advanced settings, create an inbound rule to allow connections on TCP port 22.
Get the IP Address and Test the Connection
Get the IP address:
- To connect from another machine, you’ll need the IP address of the Windows PC where SSH was enabled. Run
ipconfigat the command prompt to find it.
- To connect from another machine, you’ll need the IP address of the Windows PC where SSH was enabled. Run
Connection test:
- Use an SSH client (e.g., PuTTY, Termius) from another computer or device to connect, using the format
ssh username@your_ip_address, whereusernameis the Windows account name andyour_ip_addressis the address you just obtained.
- Use an SSH client (e.g., PuTTY, Termius) from another computer or device to connect, using the format
Modify Configuration
Avoid logging in with passwords—this is a must-avoid trap. Always use public keys to log in.
We need to disable password login and enable public-key login by adjusting the configuration.
Because the file is protected, editing it requires special privileges, and its folder and file permissions must be set to specific values. Using a script is strongly recommended.
# Check for admin rights
$elevated = [bool]([System.Security.Principal.WindowsPrincipal]::new(
[System.Security.Principal.WindowsIdentity]::GetCurrent()
).IsInRole([System.Security.Principal.WindowsBuiltInRole]::Administrator))
if (-not $elevated) {
Write-Error "Please run this script with administrator rights"
exit 1
}
# 1. Check and install the OpenSSH server if necessary
Write-Host "Checking OpenSSH server installation status..."
$capability = Get-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0
if ($capability.State -ne 'Installed') {
Write-Host "Installing OpenSSH server..."
Add-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0 | Out-Null
}
# 2. Start and set the OpenSSH service to auto-start
Write-Host "Configuring SSH service..."
$service = Get-Service sshd -ErrorAction SilentlyContinue
if (-not $service) {
Write-Error "OpenSSH service failed to install"
exit 1
}
if ($service.Status -ne 'Running') {
Start-Service sshd
}
Set-Service sshd -StartupType Automatic
# 3. Edit the configuration file
$configPath = "C:\ProgramData\ssh\sshd_config"
if (Test-Path $configPath) {
Write-Host "Backing up original configuration file..."
Copy-Item $configPath "$configPath.bak" -Force
} else {
Write-Error "Configuration file not found: $configPath"
exit 1
}
Write-Host "Modifying SSH configuration..."
$config = Get-Content -Path $configPath -Raw
# Enable pubkey authentication and disable password login
$config = $config -replace '^#?PubkeyAuthentication .*$','PubkeyAuthentication yes' `
-replace '^#?PasswordAuthentication .*$','PasswordAuthentication no'
# Ensure necessary configs are present
if ($config -notmatch 'PubkeyAuthentication') {
$config += "`nPubkeyAuthentication yes"
}
if ($config -notmatch 'PasswordAuthentication') {
$config += "`nPasswordAuthentication no"
}
# Write the new configuration
$config | Set-Content -Path $configPath -Encoding UTF8
Confirm authorized_keys Permissions
# normal user
$authKeys = "$env:USERPROFILE\.ssh\authorized_keys"
icacls $authKeys /inheritance:r /grant "$($env:USERNAME):F" /grant "SYSTEM:F"
icacls "$env:USERPROFILE\.ssh" /inheritance:r /grant "$($env:USERNAME):F" /grant "SYSTEM:F"
# administrator
$adminAuth = "C:\ProgramData\ssh\administrators_authorized_keys"
icacls $adminAuth /inheritance:r /grant "Administrators:F" /grant "SYSTEM:F"
Set Firewall Rules
# Allow SSH port
New-NetFirewallRule -DisplayName "OpenSSH Server (sshd)" -Direction Inbound -Protocol TCP -Action Allow -LocalPort 22
Add Public Keys
Normal User
# normal user
$userProfile = $env:USERPROFILE
$sshDir = Join-Path $userProfile ".ssh"
$authorizedKeysPath = Join-Path $sshDir "authorized_keys"
$PublicKeyPath = "D:\public_keys\id_rsa.pub"
# Create .ssh directory
if (-not (Test-Path $sshDir)) {
New-Item -ItemType Directory -Path $sshDir | Out-Null
}
# Set .ssh directory permissions
$currentUser = "$env:USERDOMAIN\$env:USERNAME"
$acl = Get-Acl $sshDir
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule(
$currentUser, "FullControl", "ContainerInherit,ObjectInherit", "None", "Allow"
)
$acl.AddAccessRule($rule)
Set-Acl $sshDir $acl
# Add public key
if (Test-Path $PublicKeyPath) {
$pubKey = Get-Content -Path $PublicKeyPath -Raw
if ($pubKey) {
# Ensure newline at end
if (-not $pubKey.EndsWith("`n")) {
$pubKey += "`n"
}
# Append key
Add-Content -Path $authorizedKeysPath -Value $pubKey -Encoding UTF8
# Set file permissions
$acl = Get-Acl $authorizedKeysPath
$acl.SetSecurityDescriptorRule(
(New-Object System.Security.AccessControl.FileSystemAccessRule(
$currentUser, "FullControl", "None", "None", "Allow"
))
)
Set-Acl $authorizedKeysPath $acl
}
} else {
Write-Error "Public key file not found: $PublicKeyPath"
exit 1
}
# Restart SSH service
Write-Host "Restarting SSH service..."
Restart-Service sshd
Administrator User
# administrator
$adminSshDir = "C:\ProgramData\ssh"
$adminAuthKeysPath = Join-Path $adminSshDir "administrators_authorized_keys"
$adminPublicKeyPath = "D:\public_keys\id_rsa.pub"
# Create admin SSH directory
if (-not (Test-Path $adminSshDir)) {
New-Item -ItemType Directory -Path $adminSshDir | Out-Null
}
# Set admin SSH directory permissions
$adminAcl = Get-Acl $adminSshDir
$adminRule = New-Object System.Security.AccessControl.FileSystemAccessRule(
"Administrators", "FullControl", "ContainerInherit,ObjectInherit", "None", "Allow"
)
$adminAcl.AddAccessRule($adminRule)
Set-Acl $adminSshDir $adminAcl
# Add admin public key
if (Test-Path $adminPublicKeyPath) {
$adminPubKey = Get-Content -Path $adminPublicKeyPath -Raw
if ($adminPubKey) {
# Ensure newline at end
if (-not $adminPubKey.EndsWith("`n")) {
$adminPubKey += "`n"
}
# Append key
Add-Content -Path $adminAuthKeysPath -Value $adminPubKey -Encoding UTF8
# Set file permissions
$adminAcl = Get-Acl $adminAuthKeysPath
$adminAcl.SetSecurityDescriptorRule(
(New-Object System.Security.AccessControl.FileSystemAccessRule(
"Administrators", "FullControl", "None", "None", "Allow"
))
)
Set-Acl $adminAuthKeysPath $adminAcl
}
} else {
Write-Error "Admin public key file not found: $adminPublicKeyPath"
exit 1
}
# Restart SSH service
Write-Host "Restarting SSH service..."
Restart-Service sshd
Understanding Windows Networking_WFP
- Understanding Windows Networking_WFP
Understanding Windows Networking
- Understanding Windows Networking
WFP
Terminology
https://learn.microsoft.com/en-us/windows/win32/fwp/object-model
https://learn.microsoft.com/en-us/windows/win32/fwp/basic-operation
https://learn.microsoft.com/en-us/windows-hardware/drivers/network
callout: A callout provides functionality that extends the capabilities of the Windows Filtering Platform. A callout consists of a set of callout functions and a GUID key that uniquely identifies the callout.
callout driver: A callout driver is a driver that registers callouts with the Windows Filtering Platform. A callout driver is a type of filter driver.
callout function: A callout function is a function that is called by the Windows Filtering Platform to perform a specific task. A callout function is associated with a callout.
filter: A filter is a set of functions that are called by the Windows Filtering Platform to perform filtering operations. A filter consists of a set of filter functions and a GUID key that uniquely identifies the filter.
filter engine: The filter engine is the component of the Windows Filtering Platform that performs filtering operations. The filter engine is responsible for calling the filter functions that are registered with the Windows Filtering Platform.
filter layer: A filter layer is a set of functions that are called by the Windows Filtering Platform to perform filtering operations. A filter layer consists of a set of filter layer functions and a GUID key that uniquely identifies the filter layer.
The dispatcher queue triggers callbacks as soon as possible without waiting for the queue to fill, thus satisfying real-time requirements.
When the user callback is slow, blocked packets are inserted into the next queue whenever possible, up to a queue limit of 256. Any additional blocked packets are buffered by the system. Rough testing shows a buffer capacity of around 16,500; this system cache size can vary with machine performance and configuration.
When the user callback processes a packet, there are two packet entities:
- Kernel packet: Released in bulk after the callback finishes processing the queue. Therefore, when the callback is slow, one callback execution can lock up to 256 system packet buffers.
- Copy in callback: Released immediately after the individual packet is processed.
Copying and assembling packets in FwppNetEvent1Callback does not touch the original packets, so business operations remain unaffected.
Subscribing with template filters can reduce the number of packets that need processing:
filterCondition
An array of FWPM_FILTER_CONDITION0 structures containing distinct filter conditions (duplicate filter conditions will produce an error). All conditions must be true for the action to occur; in other words, the conditions are AND’ed together. If no conditions are provided, the action is always performed.
- Identical filters cannot be used.
- The relationship among all filters is logical AND—all must be satisfied.
- Microsoft documentation lists eight supported filters, but in practice many more are supported.
FWPM_CONDITION_IP_PROTOCOL
The IP protocol number, as specified in RFC 1700.
FWPM_CONDITION_IP_LOCAL_ADDRESS
The local IP address.
FWPM_CONDITION_IP_REMOTE_ADDRESS
The remote IP address.
FWPM_CONDITION_IP_LOCAL_PORT
The local transport protocol port number. For ICMP, this is the message type.
FWPM_CONDITION_IP_REMOTE_PORT
The remote transport protocol port number. For ICMP, this is the message code.
FWPM_CONDITION_SCOPE_ID
The interface IPv6 scope identifier; reserved for internal use.
FWPM_CONDITION_ALE_APP_ID
The full path of the application.
FWPM_CONDITION_ALE_USER_ID
The identification of the local user.
Enumerating registered subscriptions shows two existing ones. Their sessionKey GUIDs provide no clues about the registering identity. Analysis shows each implements:
- Subscription to all
FWPM_NET_EVENT_TYPE_CLASSIFY_DROPpackets to collect statistics on dropped packets. - Subscription to all
FWPM_NET_EVENT_TYPE_CLASSIFY_ALLOWpackets for traffic accounting.
Both subscriptions use the condition filter FWPM_CONDITION_NET_EVENT_TYPE (206e9996-490e-40cf-b831-b38641eb6fcb), confirming that more filters can be applied than the eight listed in Microsoft’s documentation.
Further investigation indicates that the user-mode API can only capture drop events. Non-drop events must be obtained via kernel mode, so a micro-segmentation solution cannot use FWPM_CONDITION_NET_EVENT_TYPE to gather events.
Understanding Windows Event Tracing (ETW)
- Understanding Windows Event Tracing (ETW)
Understanding ETW
Some unnecessary information has been filtered out; see the complete documentation at: https://docs.microsoft.com/en-us/windows/win32/etw/event-tracing-portal
Understanding the Basics
https://learn.microsoft.com/en-us/windows/win32/etw/about-event-tracing
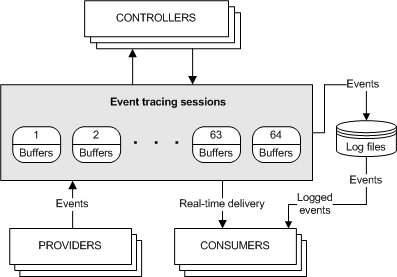
Session
There are four kinds of sessions:
| Session Type | Usage | Limitations | Characteristics |
|---|---|---|---|
| Event Tracing Session(Standard ETW) | 1. EVENT_TRACE_PROPERTIES 2. StartTrace: create a session 3. EnableTrace 1. EnableTrace for classic providers 2. EnableTraceEx for manifest-based providers 4. ControlTrace stop the session | - A manifest-based provider can deliver events to at most 8 sessions. - A classic provider can only serve one session. - The last session to enable a provider supersedes any earlier sessions. | Standard ETW. |
| SystemTraceProvider Session | 1. EVENT_TRACE_PROPERTIES → EnableFlags 2. StartTrace 3. ControlTrace to stop the session | - SystemTraceProvider is a kernel-mode provider that supplies a set of predefined kernel events. - The NT Kernel Logger session is a predefined system session that records a specified set of kernel events. - Windows 7/Windows Server 2008 R2 only the NT Kernel Logger session may use SystemTraceProvider. - Windows 8/Windows Server 2012 SystemTraceProvider can feed 8 logger sessions, two of which are reserved for NT Kernel Logger and Circular Kernel Context Logger. - Windows 10 20348 and later, individual System providers can be controlled separately. | Obtain kernel predefined events. |
| AutoLogger Session | 1. Edit the registry 2. EnableTraceEx 3. ControlTrace to stop the session | - The Global Logger Session is a special, standalone session that records events during system boot. - Ordinary AutoLogger sessions must explicitly enable providers; Global Logger does not. - AutoLogger does not support NT Kernel Logger events; only Global Logger does. - Impacts boot time—use sparingly. | Record OS boot-time events. |
| Private Logger Session | — | - User-mode ETW - Used only within a process - Not counted toward the 64-session concurrency limit. | Per-process only. |
Tools
- logman
- wevtutil
- XPath query example:
wevtutil qe Security /c:2 /q:"*[System[EventID=5157]]" /f:text
- XPath query example:
- tracelog
- To use the Visual Studio
tracelogtool, you can dynamically add and remove ETW Providers and ETW Sessions at runtime.
- To use the Visual Studio
- mc
- etw-providers-docs
wireguard configuration
- wireguard configuration
wireguard Configuration
Firewall Configuration
wireguard /installtunnelservice <wg_conf_path>
wg show
Get-NetConnectionProfile
Get-NetAdapter
Get-NetFirewallProfile
Set-NetFirewallProfile -Profile domain,public,private -DisabledInterfaceAliases <wg_config_name>
Set-NetIPInterface -ifindex <interface index> -Forwarding Enabled
New-NetFirewallRule -DisplayName "@wg1" -Direction Inbound -RemoteAddress 10.66.66.1/24 -Action Allow
New-NetFirewallRule -DisplayName "@wg1" -Direction Outbound -RemoteAddress 10.66.66.1/24 -Action Allow
# Locate the blocking cause
auditpol /set /subcategory:"{0CCE9225-69AE-11D9-BED3-505054503030}" /success:disable /failure:enable
wevtutil qe Security /q:"*[System/EventID=5152]" /c:5 /rd:true /f:text
auditpol /set /subcategory:"{0CCE9225-69AE-11D9-BED3-505054503030}" /success:disable /failure:disable
Windows Blocking Network Traffic Capture
- Windows Blocking Network Traffic Capture
Windows Blocking Network Traffic Capture
- Windows Blocking Network Traffic Capture
- Need to identify blocked traffic, including outbound and inbound.
- Two ways of blocking: by connection or by packet. Packet drops occur frequently and the reason must be audited; connection‐oriented blocks align better with real-world monitoring.
- Many normally processed packets may also be dropped, so we must distinguish drops from actual blocks—we focus on blocks.
Setting Up a Test Project
WFP mainly runs in user mode and partly in kernel mode, exposed as drivers. The test setup is complex.
Recommended: run a separate physical machine for testing, compile on the dev box, then copy and remotely debug on the test machine.
For those with limited resources, local debugging on the same machine is also possible.
- Microsoft WFP Sample Project
- Focus only on: Windows-driver-samples\network\trans\WFPSampler
- WFPSampler Guide
Build Issues:
Other Issues:
Capturing Block Events via Auditing
By default, auditing for WFP is off.
- Audit can be enabled by category (via Group Policy Object Editor MMC, Local Security Policy MMC, or auditpol.exe).
- Audit can also be enabled by subcategory with auditpol.exe.
- Always use GUIDs—otherwise localized display strings break cross-language systems.
- Audit uses circular logs of 128 KB—low resource impact.
Categories https://docs.microsoft.com/en-us/windows/win32/secauthz/auditing-constants
| Category/Subcategory | GUID |
|---|---|
| … | … |
| Object Access | {6997984A-797A-11D9-BED3-505054503030} |
| Policy Change | {6997984D-797A-11D9-BED3-505054503030} |
| … | … |
Object Access subcategories and their GUIDs https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-gpac/77878370-0712-47cd-997d-b07053429f6d
| Object Access Subcategory | Subcategory GUID | Inclusion Setting |
|---|---|---|
| … | … | … |
| Filtering Platform Packet Drop | {0CCE9225-69AE-11D9-BED3-505054503030} | No Auditing |
| Filtering Platform Connection | {0CCE9226-69AE-11D9-BED3-505054503030} | No Auditing |
| Other Object Access Events | {0CCE9227-69AE-11D9-BED3-505054503030} | No Auditing |
| … | … | … |
Policy Change subcategories and GUIDs:
| Policy Change Subcategory | Subcategory GUID |
|---|---|
| Audit Policy Change | {0CCE922F-69AE-11D9-BED3-505054503030} |
| Authentication Policy Change | {0CCE9230-69AE-11D9-BED3-505054503030} |
| Authorization Policy Change | {0CCE9231-69AE-11D9-BED3-505054503030} |
| MPSSVC Rule-Level Policy Change | {0CCE9232-69AE-11D9-BED3-505054503030} |
| Filtering Platform Policy Change | {0CCE9233-69AE-11D9-BED3-505054503030} |
| Other Policy Change Events | {0CCE9234-69AE-11D9-BED3-505054503030} |
# auditpol reference: https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/auditpol
# This section focuses on the 'Object Access' category
# List available fields
# -v shows GUID, -r produces CSV report
auditpol /list /category /v
auditpol /list /subcategory:* /v
# Get audit settings for a subcategory
auditpol /get /category:'Object Access' /r | ConvertFrom-Csv | Get-Member
# Query subcategory GUID
auditpol /get /category:'Object Access' /r | ConvertFrom-Csv | Format-Table Subcategory,'Subcategory GUID','Inclusion Setting'
# Lookup subcategory
auditpol /list /subcategory:"Object Access","Policy Change" -v
# Backup
auditpol /backup /file:d:\audit.bak
# Restore
auditpol /restore /file:d:\audit.bak
# Modify Policy
# **Policy Change** | {6997984D-797A-11D9-BED3-505054503030}
auditpol /set /category:"{6997984D-797A-11D9-BED3-505054503030}" /success:disable /failure:disable
# Filtering Platform Policy Change | {0CCE9233-69AE-11D9-BED3-505054503030}
auditpol /set /subcategory:"{0CCE9233-69AE-11D9-BED3-505054503030}" /success:enable /failure:enable
# **Object Access** | {6997984A-797A-11D9-BED3-505054503030}
auditpol /get /category:"{6997984A-797A-11D9-BED3-505054503030}"
auditpol /set /category:"{6997984A-797A-11D9-BED3-505054503030}" /success:disable /failure:disable
# Filtering Platform Packet Drop | {0CCE9225-69AE-11D9-BED3-505054503030}
auditpol /set /subcategory:"{0CCE9225-69AE-11D9-BED3-505054503030}" /success:disable /failure:enable
# Filtering Platform Connection | {0CCE9226-69AE-11D9-BED3-505054503030}
auditpol /set /subcategory:"{0CCE9226-69AE-11D9-BED3-505054503030}" /success:disable /failure:enable
# Read audit logs
$Events = Get-WinEvent -LogName 'Security'
foreach ($event in $Events) {
ForEach ($line in $($event.Message -split "`r`n")) {
Write-Host $event.RecordId ':' $Line
break
}
}
Event Details:
| Event ID | Explanation |
|---|---|
| 5031(F) | The Windows Firewall Service blocked an application from accepting incoming connections on the network. |
| 5150(-) | The Windows Filtering Platform blocked a packet. |
| 5151(-) | A more restrictive Windows Filtering Platform filter has blocked a packet. |
| 5152(F) | The Windows Filtering Platform blocked a packet. |
| 5153(S) | A more restrictive Windows Filtering Platform filter has blocked a packet. |
| 5154(S) | The Windows Filtering Platform has permitted an application or service to listen on a port for incoming connections. |
| 5155(F) | The Windows Filtering Platform has blocked an application or service from listening on a port for incoming connections. |
| 5156(S) | The Windows Filtering Platform has permitted a connection. |
| 5157(F) | The Windows Filtering Platform has blocked a connection. |
| 5158(S) | The Windows Filtering Platform has permitted a bind to a local port. |
| 5159(F) | The Windows Filtering Platform has blocked a bind to a local port. |
Events to Focus On:
- Audit Filtering Platform Packet Drop
These events generate huge volumes; focus on 5157, which records almost the same data but per-connection rather than per-packet.
Failure volume is typically very high for this subcategory and mainly useful for troubleshooting. To monitor blocked connections, 5157(F): The Windows Filtering Platform has blocked a connection is recommended since it contains nearly identical information and generates per-connection instead of per-packet.
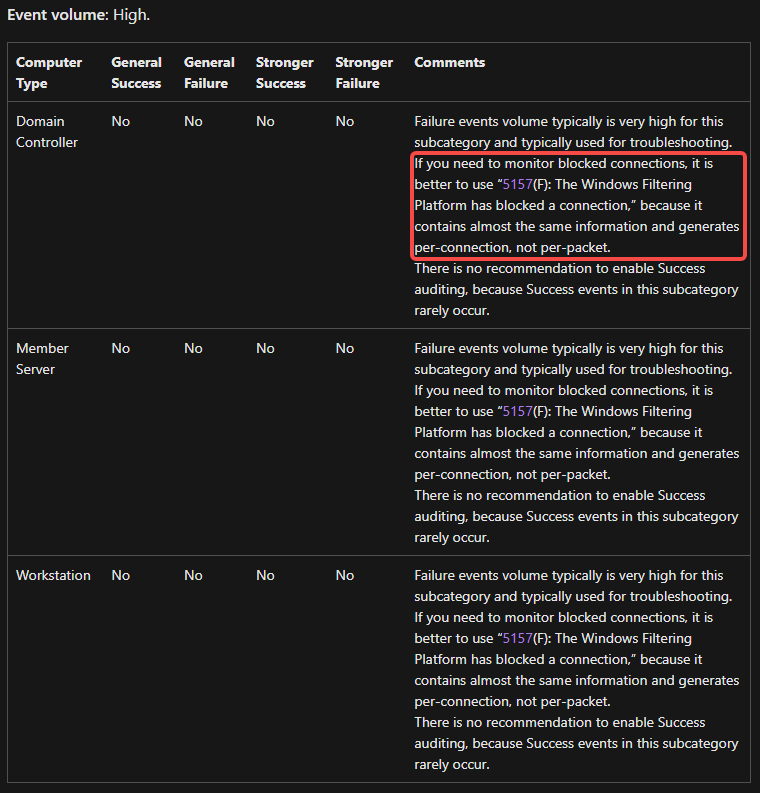
- Audit Filtering Platform Connection
- It is best to monitor only failure events such as blocked connections; track allowed connections only when necessary.
- 5031
- If there are no firewall rules (Allow or Deny) for a specific application in Windows Firewall, traffic will be dropped at the WFP layer, which by default denies all inbound connections.
51505151- 5155
- 5157
- 5159
Obtaining Provider Information
# List security-related providers
Get-WinEvent -ListProvider "*Security*" | Select-Object ProviderName,Id
# Microsoft-Windows-Security-Auditing 54849625-5478-4994-a5ba-3e3b0328c30d
# Show tasks for a provider
Get-WinEvent -ListProvider "Microsoft-Windows-Security-Auditing" | Select-Object -ExpandProperty tasks
# SE_ADT_OBJECTACCESS_FIREWALLCONNECTION 12810 Filtering Platform Connection 00000000-0000-0000-0000-000000000000
| ProviderName | Id |
|---|---|
| Security Account Manager | 00000000-0000-0000-0000-000000000000 |
| Security | 00000000-0000-0000-0000-000000000000 |
| SecurityCenter | 00000000-0000-0000-0000-000000000000 |
| Microsoft-Windows-Security-SPP-UX-GenuineCenter-Logging | fb829150-cd7d-44c3-af5b-711a3c31cedc |
| Microsoft-Windows-Security-Mitigations | fae10392-f0af-4ac0-b8ff-9f4d920c3cdf |
| Microsoft-Windows-VerifyHardwareSecurity | f3f53c76-b06d-4f15-b412-61164a0d2b73 |
| Microsoft-Windows-SecurityMitigationsBroker | ea8cd8a5-78ff-4418-b292-aadc6a7181df |
| Microsoft-Windows-Security-Adminless | ea216962-877b-5b73-f7c5-8aef5375959e |
| Microsoft-Windows-Security-Vault | e6c92fb8-89d7-4d1f-be46-d56e59804783 |
| Microsoft-Windows-Security-Netlogon | e5ba83f6-07d0-46b1-8bc7-7e669a1d31dc |
| Microsoft-Windows-Security-SPP | e23b33b0-c8c9-472c-a5f9-f2bdfea0f156 |
| Microsoft-Windows-Windows Firewall With Advanced Security | d1bc9aff-2abf-4d71-9146-ecb2a986eb85 |
| Microsoft-Windows-Security-SPP-UX-Notifications | c4efc9bb-2570-4821-8923-1bad317d2d4b |
| Microsoft-Windows-Security-SPP-UX-GC | bbbdd6a3-f35e-449b-a471-4d830c8eda1f |
| Microsoft-Windows-Security-Kerberos | 98e6cfcb-ee0a-41e0-a57b-622d4e1b30b1 |
| Microsoft-Windows-Security-ExchangeActiveSyncProvisioning | 9249d0d0-f034-402f-a29b-92fa8853d9f3 |
| Microsoft-Windows-NetworkSecurity | 7b702970-90bc-4584-8b20-c0799086ee5a |
| Microsoft-Windows-Security-SPP-UX | 6bdadc96-673e-468c-9f5b-f382f95b2832 |
| Microsoft-Windows-Security-Auditing | 54849625-5478-4994-a5ba-3e3b0328c30d |
| Microsoft-Windows-Security-LessPrivilegedAppContainer | 45eec9e5-4a1b-5446-7ad8-a4ab1313c437 |
| Microsoft-Windows-Security-UserConsentVerifier | 40783728-8921-45d0-b231-919037b4b4fd |
| Microsoft-Windows-Security-IdentityListener | 3c6c422b-019b-4f48-b67b-f79a3fa8b4ed |
| Microsoft-Windows-Security-EnterpriseData-FileRevocationManager | 2cd58181-0bb6-463e-828a-056ff837f966 |
| Microsoft-Windows-Security-Audit-Configuration-Client | 08466062-aed4-4834-8b04-cddb414504e5 |
| Microsoft-Windows-Security-IdentityStore | 00b7e1df-b469-4c69-9c41-53a6576e3dad |
Triggering a Block Event
Warning: Creating block filters affects other software on the host!
You can immediately clean up with .\WFPSampler.exe -clean.
Steps:
Enable auditing for Filtering Platform Connection:
auditpol /set /subcategory:"{0CCE9226-69AE-11D9-BED3-505054503030}" /success:enable /failure:enableOpen Event Viewer, create a Custom View/filter for IDs 5155, 5157, 5159.
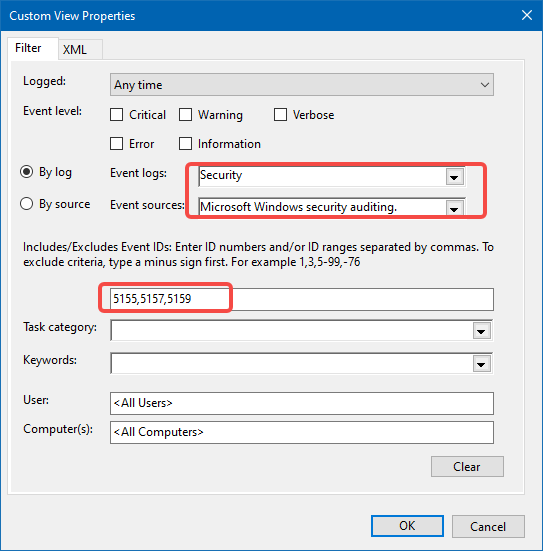
Add a WFP filter using WFPSampler.exe to block listening on port 80:
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_LISTEN_V4 -iplp 80Run a third-party (non-IIS) HTTP server—here we use nginx on port 80. Starting it triggers event 5155.
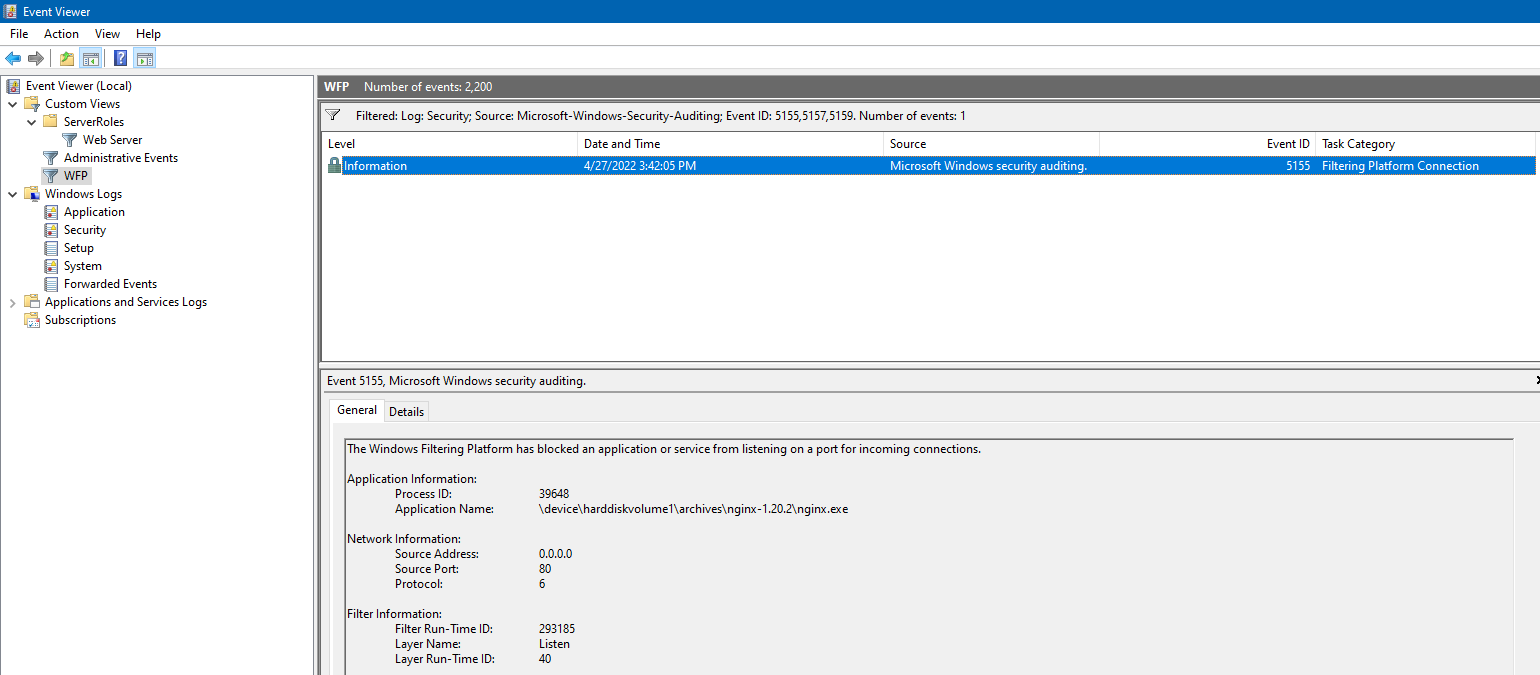
Clean up the filter:
.\WFPSampler.exe -cleanDisable auditing:
auditpol /set /category:"{0CCE9226-69AE-11D9-BED3-505054503030}" /success:disable /failure:disable
# 5155: an application or service was blocked from listening on a port
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_LISTEN_V4
# 5157: a connection was blocked
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_CONNECT_V4
# 5159: binding to a local port was blocked
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_RESOURCE_ASSIGNMENT_V4
# Other
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_RESOURCE_ASSIGNMENT_V4_DISCARD
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4_DISCARD
.\WFPSampler.exe -s BASIC_ACTION_BLOCK -l FWPM_LAYER_ALE_AUTH_CONNECT_V4_DISCARD
# List a WFP filter by ID:
netsh wfp show filters
# Get layer IDs:
netsh wfp show state
Monitoring Network Events (NET_EVENT)
- Events support both enumeration and subscription.
- Enumeration allows filter criteria, querying events within a time window.
- Subscriptions inject a callback to deliver events in real time.
Supported event types:
typedef enum FWPM_NET_EVENT_TYPE_ {
FWPM_NET_EVENT_TYPE_IKEEXT_MM_FAILURE = 0,
FWPM_NET_EVENT_TYPE_IKEEXT_QM_FAILURE,
FWPM_NET_EVENT_TYPE_IKEEXT_EM_FAILURE,
FWPM_NET_EVENT_TYPE_CLASSIFY_DROP,
FWPM_NET_EVENT_TYPE_IPSEC_KERNEL_DROP,
FWPM_NET_EVENT_TYPE_IPSEC_DOSP_DROP,
FWPM_NET_EVENT_TYPE_CLASSIFY_ALLOW,
FWPM_NET_EVENT_TYPE_CAPABILITY_DROP,
FWPM_NET_EVENT_TYPE_CAPABILITY_ALLOW,
FWPM_NET_EVENT_TYPE_CLASSIFY_DROP_MAC,
FWPM_NET_EVENT_TYPE_LPM_PACKET_ARRIVAL,
FWPM_NET_EVENT_TYPE_MAX
} FWPM_NET_EVENT_TYPE;
Enumeration filter fields (FWPM_NET_EVENT_ENUM_TEMPLATE):
| Value | Meaning |
|---|---|
| FWPM_CONDITION_IP_PROTOCOL | The IP protocol number, as specified in RFC 1700. |
| FWPM_CONDITION_IP_LOCAL_ADDRESS | The local IP address. |
| FWPM_CONDITION_IP_REMOTE_ADDRESS | The remote IP address. |
| FWPM_CONDITION_IP_LOCAL_PORT | The local transport protocol port number. For ICMP, the message type. |
| FWPM_CONDITION_IP_REMOTE_PORT | The remote transport protocol port number. For ICMP, the message code. |
| FWPM_CONDITION_SCOPE_ID | The interface IPv6 scope identifier. Reserved for internal use. |
| FWPM_CONDITION_ALE_APP_ID | The full path of the application. |
| FWPM_CONDITION_ALE_USER_ID | The identification of the local user. |
Outside of drivers, only basic drop events are returned.
Monitoring Network Connections (NetConnection)
Compared to monitoring network events, monitoring connections requires higher privileges.
callback approach
The caller needs FWPM_ACTRL_ENUM access to the connection objects’ containers and FWPM_ACTRL_READ access to the connection objects. See Access Control for more information.
Monitoring network connections has not yet succeeded.
I found a similar issue: Receiving in/out traffic stats using WFP user-mode API. It matches the behavior I observed—none of the subscribing functions receive any notifications, giving no events and no errors. Neither enabling auditing nor elevating privileges helped. Some noted that non-kernel mode can only receive drop events, which is insufficient for obtaining block events.
Example of adding a security descriptor: https://docs.microsoft.com/en-us/windows/win32/fwp/reserving-ports
Application Layer Enforcement (ALE) Introduction
- ALE comprises a set of kernel-mode filters that support stateful filtering.
- Filters at the ALE layer can authorize connection creation, port allocation, socket management, raw socket creation, and promiscuous-mode reception.
- Classification of ALE-layer filters is based on the connection or socket; filters in other layers can only classify based on individual packets.
- ALE filter reference: ale-layers
- More filter reference: filtering-layer-identifiers
Coding Notes
Most WFP functions can be invoked from either user mode or kernel mode. However, user-mode functions return a DWORD representing a Win32 error code, whereas kernel-mode functions return an NTSTATUS representing an NT status code.
Therefore, functions share the same names and semantics across modes but have differing signatures. Separate user-mode and kernel-mode headers are required: user-mode header file names end with “u”, and kernel-mode ones end with “k”.
Conclusion
Our requirement is merely to know when events occur; real-time handling is unnecessary, and developing a kernel driver would introduce greater risk. Consequently, we’ll rely on event auditing and monitor event log generation to acquire block events.
A dedicated thread will use NotifyChangeEventLog to watch for new log records.
Appendix
WFP Architecture
WFP (Windows Filter Platform) 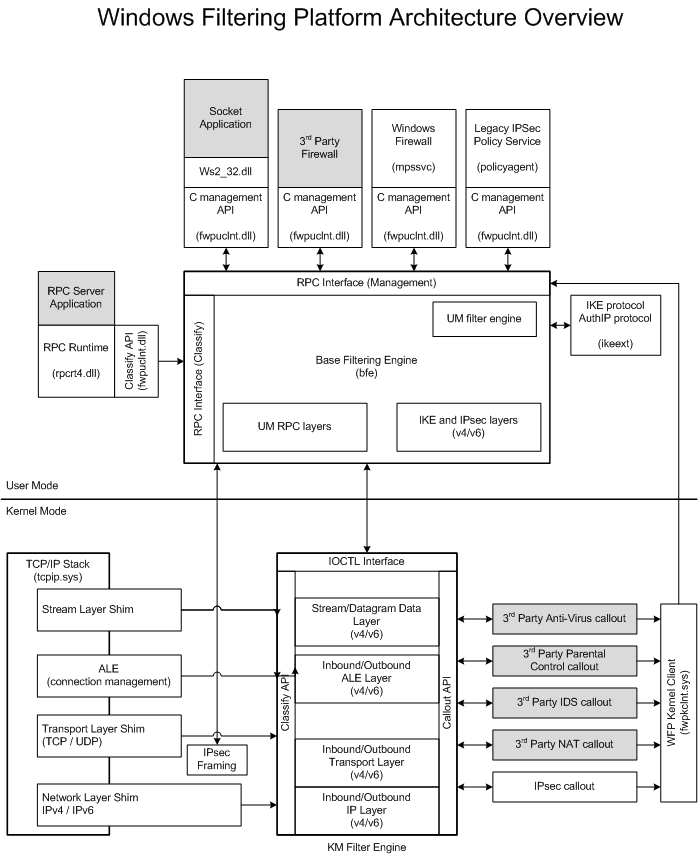
Data Flow
Data flow:
- A packet enters the network stack.
- The network stack finds and invokes a shim.
- The shim initiates classification at a particular layer.
- During classification, filters are matched, and the resulting action is applied. (See Filter Arbitration.)
- If any callout filters match, their corresponding callouts are invoked.
- The shim enforces the final filtering decision (e.g., drop the packet).
Reference Links
Windows Firewall Management – netsh
- Windows Firewall Management – netsh
Windows Firewall Management – netsh
Management Tools
netsh advfirewall
# Export firewall rules
netsh advfirewall export advfirewallpolicy.wfw
# Import firewall rules
netsh advfirewall import advfirewallpolicy.wfw
# View firewall state
netsh advfirewall show allprofiles state
# View firewall default policy
netsh advfirewall show allprofiles firewallpolicy
# netsh advfirewall set allprofiles firewallpolicy blockinbound,allowoutbound
# netsh advfirewall set allprofiles firewallpolicy blockinbound,blockoutbound
# View firewall settings
netsh advfirewall show allprofiles settings
# Enable firewall
netsh advfirewall set allprofiles state on
# Disable firewall
netsh advfirewall set allprofiles state off
# Display firewall rules
netsh advfirewall firewall show rule name=all
# View firewall status
netsh advfirewall monitor show firewall
netsh firewall (deprecated)
# Display firewall state
netsh firewall show state
netsh mbn (Mobile Broadband network)
netsh wfp
# Display firewall state
netsh wfp show state
# Display firewall filters
netsh wfp show filters
Windows Resources
- Windows Resources
Windows Resources Collection
This section lists only some common Windows tools for debugging, troubleshooting, and testing. Tools for packing/unpacking, encryption/decryption, file editors, and programming tools are omitted for brevity.
Tools
Monitoring & Analysis
| Tool Name | Download Link | Description |
|---|---|---|
| DebugView | https://docs.microsoft.com/zh-cn/sysinternals/downloads/debugview | A Sysinternals utility for capturing and controlling kernel and user-mode debug output. |
| Process Monitor | https://docs.microsoft.com/zh-cn/sysinternals/downloads/procmon | A real-time Sysinternals tool that monitors file system, registry, process, thread, and DLL activity to help troubleshoot issues. |
| Process Explorer | https://docs.microsoft.com/zh-cn/sysinternals/downloads/process-explorer | A Sysinternals process viewer that inspects loaded DLLs, call stacks, and which processes have opened a file. |
| WinObj | https://docs.microsoft.com/zh-cn/sysinternals/downloads/winobj | A Sysinternals viewer for the Object Manager namespace; it uses native APIs without loading drivers—see WinObjEx64 for an open-source implementation on GitHub. |
| WinObjEx64 | https://github.com/hfiref0x/WinObjEx64 | An open-source, advanced Object Manager namespace viewer. |
| Handle | https://docs.microsoft.com/zh-cn/sysinternals/downloads/handle | A Sysinternals utility showing which file or directory is held by a running process. |
| Sysinternals Suite | https://live.sysinternals.com/ | The complete suite of Sysinternals utilities—only the most frequently used are listed here to avoid clutter. |
| CPU-Z | https://www.cpuid.com/softwares/cpu-z.html | Real-time CPU monitoring tool. |
| ProcMonX | https://github.com/zodiacon/ProcMonX | An open-source C# implementation using ETW to provide functionality similar to Process Monitor. |
| ProcMonXv2 | https://github.com/zodiacon/ProcMonXv2 | The second open-source C# ETW-based alternative to Process Monitor. |
| Process Hacker | https://github.com/processhacker/processhacker | An open-source Process Explorer-like tool with GPU information support. |
| API Monitor | http://www.rohitab.com/apimonitor | Traces API calls to show how applications/services interact, helps detect bugs, and can modify input/output parameters. |
| Dependency Walker | http://www.dependencywalker.com/ | Scans any 32- or 64-bit Windows module and lists all exported functions. |
| DeviceTree | http://www.osronline.com/article.cfm%5earticle=97.htm | Displays all driver objects and device stack information in the system. |
| Unlocker | https://www.softpedia.com/get/System/System-Miscellaneous/Unlocker.shtml | Unlocks files held by running processes—many similar open-source tools are available. |
| RpcView | https://github.com/silverf0x/RpcView | Shows and decompiles live RPC interfaces on the system—useful when analyzing RPC services. |
| RequestTrace | https://the-sz.com/products/rt/ | Displays IRPs, SRBs, URBs, and related buffers on Windows; mostly redundant as WinDbg covers the same traces but handy without a debugger. |
| IRPMon | https://github.com/MartinDrab/IRPMon | Hooks driver objects to monitor IRP traffic and other driver requests, similar to RequestTrace and IrpTracker. |
| IRPTrace | https://github.com/haidragon/drivertools | Contains a collection of additional tools. |
AntiRootkit Tools
| Tool Name | Download Link | Description |
|---|---|---|
| PcHunter | https://www.anxinsec.com/view/antirootkit/ | Security analysis tool that bypasses rootkits via direct disk, registry, network, etc., showing detailed info on threads, processes, and kernel modules. |
| Windows-Kernel-Explorer | https://github.com/AxtMueller/Windows-Kernel-Explorer | Closed-source alternative to PcHunter, useful when newer OS support is missing. |
| PowerTool | Rarely updated. Developed by a colleague of a friend; reportedly messy codebase. | |
| py | https://github.com/antiwar3/py | PiaoYun ARK—open-source rootkit scanner. |
PE Tools
| Tool Name | Download Link | Description |
|---|---|---|
| CFF Explorer | https://ntcore.com/?page_id=388 | A nice PE explorer. |
| ExeinfoPe | http://www.exeinfo.xn.pl/ | – |
Reverse & Debug
| Tool Name | Download Link | Description | |
|---|---|---|---|
| Ghidra | https://www.nsa.gov/resources/everyone/ghidra/ | A software reverse-engineering (SRE) suite created by the NSA Research Directorate to support cybersecurity missions. | |
| IDA | https://down.52pojie.cn/ | Famous but closed-source interactive disassembler—latest cracks (v7.5) on 52pojie forum. | |
| dnSpy | https://github.com/dnSpy/dnSpy | .NET decompiler; effectively provides source code for unobfuscated .NET binaries if the framework is familiar to you. | |
| OllyDbg | https://down.52pojie.cn/Tools/Debuggers// | Popular debugger with many plugins; closed-source and only for 32-bit binaries. | |
| x64dbg | https://x64dbg.com/ | Open-source debugger for x86/x64 binaries—more convenient than WinDbg yet similar plugin support; recommended over OllyDbg. | |
| Cheat Engine | https://www.cheatengine.org/ | Memory-search & manipulation Swiss-army knife; offers many advanced reverse-engineering features. | |
| VirtualKD-Redux | https://github.com/4d61726b/VirtualKD-Redux/releases | Fully-automated WinDbg virtual-machine debugging without env vars; supports latest VMware. | |
| Driver Loader | http://www.osronline.com/article.cfm%5Earticle=157.htm | OSR tool for installing, loading, and unloading drivers. | |
| reverse-engineering | https://github.com/wtsxDev/reverse-engineering | A curated list of almost every tool you need for reverse engineering. |
Injection Tools
| Tool Name | Download Link | Description | |
|---|---|---|---|
| yapi | https://github.com/ez8-co/yapi | Simple open-source DLL injector for x64/x86 processes—good for learning from the source; supports cross-bit-width injection from 32-bit to 64-bit. | |
| Xenos | https://github.com/DarthTon/Xenos | Open-source injector using the famous Blackbone library; supports kernel-level injection. | |
| ExtremeInjector | https://github.com/master131/ExtremeInjector | Easy-to-use application-layer injector featuring cross-bit-width injection from 32-bit to 64-bit. |
Network
| Tool Name | Download Link | Description |
|---|---|---|
| Fiddler | https://www.telerik.com/fiddler | Powerful HTTPS man-in-the-middle proxy without a certificate hassle; scriptable; ships with an SDK. |
| Wireshark | https://www.wireshark.org/download.html | No introduction needed. |
| Burp Suite | https://portswigger.net/burp | The go-to web proxy for pentesters. Requires JDK; cracked versions available on 52pojie. |
Stress Testing Tools
| Tool Name | Download Link | Description |
|---|---|---|
| Driver Verifier | https://docs.microsoft.com/en-us/windows-hardware/drivers/devtest/driver-verifier | Built-in driver stability and stress tester. |
| Application Verifier | https://docs.microsoft.com/en-us/windows-hardware/drivers/devtest/application-verifier | Built-in application-layer stress tester. |
| CPUStress | https://docs.microsoft.com/en-us/sysinternals/downloads/cpustres | Pushes CPU to full load to test application stability and responsiveness under extreme conditions. |
Others
| Tool Name | Download Link | Description |
|---|---|---|
| game-hacking | https://github.com/dsasmblr/game-hacking | – |
| awesome-malware-analysis | https://github.com/rootkiter/awesome-malware-analysis | Curated list of malware-analysis tools |
| drawio | https://github.com/jgraph/drawio-desktop | The ultimate diagramming tool |
| RazorSQL | https://www.razorsql.com/ | GUI for SQLite3 databases |
| Git Learning Notes | https://github.com/No-Github/1earn/blob/master/1earn/Develop/%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6/Git%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0.md | Version management with Git |
| Markdown Syntax Learning | https://github.com/No-Github/1earn/blob/master/1earn/Develop/%E6%A0%87%E8%AE%B0%E8%AF%AD%E8%A8%80/Markdown/Markdown%E8%AF%AD%E6%B3%95%E5%AD%A6%E4%B9%A0.md | Markdown reference |
Code
Operating System
| Tool Name | Download Link | Description |
|---|---|---|
| ReactOS | https://github.com/reactos/reactos | An open-source OS aiming for Windows 2000 driver binary compatibility. |
| wrk-v1.2 | https://github.com/jmcjmmcjc/wrk-v1.2 | Partial Windows NT 5.2 source code. |
| WinNT4 | https://github.com/ZoloZiak/WinNT4 | Windows NT4 kernel source code. |
| whids | https://github.com/0xrawsec/whids/tree/a826d87e0d035daac10bfa96b530c5deff6b9915 | Open source EDR for Windows. |
Kernel Examples
| Tool Name | Download Link | Description |
|---|---|---|
| CPPHelper | https://github.com/Chuyu-Team/CPPHelper | Basic C++ helper class library. |
| cpp_component | https://github.com/skyformat99/cpp_component | Encapsulation of common C/C++ features. |
| WinToolsLib | https://github.com/deeonis-ru/WinToolsLib | Suite of classes for Windows programming. |
| KDU | https://github.com/hfiref0x/KDU | – |
| KTL | https://github.com/MeeSong/KTL | – |
| Kernel-Bridge | https://github.com/HoShiMin/Kernel-Bridge | – |
| KernelForge | https://github.com/killvxk/KernelForge | – |
| ExecutiveCallbackObjects | https://github.com/0xcpu/ExecutiveCallbackObjects | Research on various kernel-mode callbacks. |
| SyscallHook | https://github.com/AnzeLesnik/SyscallHook | System-call hook for Windows 10 20H1. |
| Antivirus_R3_bypass_demo | https://github.com/huoji120/Antivirus_R3_bypass_demo | Eliminates AV via both R3 0-day and R0 0-day. |
| KernelHiddenExecute | https://github.com/zouxianyu/KernelHiddenExecute | Hide code/data in kernel address space. |
| DriverInjectDll | https://github.com/strivexjun/DriverInjectDll | Kernel-mode global and memory-based injection for Win7–Win10. |
| zwhawk | https://github.com/eLoopWoo/zwhawk | Kernel rootkit providing remote command/control. |
| ZeroBank-ring0-bundle | https://github.com/Trietptm-on-Coding-Algorithms/ZeroBank-ring0-bundle | Kernel-mode rootkit for remote server communication. |
| kdmapper | https://github.com/z175/kdmapper | Manual driver mapper (educational/outdated). |
| antispy | https://github.com/mohuihui/antispy | Free but powerful AV & rootkit detection toolkit. |
| windows_kernel_resources | https://github.com/sam-b/windows_kernel_resources | – |
| HookLib | https://github.com/HoShiMin/HookLib | User- and kernel-mode hooking library. |
| Kernel-Whisperer | https://github.com/BrunoMCBraga/Kernel-Whisperer | Kernel module utilities. |
| SQLiteCpp | https://github.com/SRombauts/SQLiteCpp | Smart, easy-to-use C++ SQLite3 wrapper. |
| awesome-windows-kernel-security-development | https://github.com/ExpLife0011/awesome-windows-kernel-security-development | Curated collection of Windows kernel security projects. |
VT Technology
| Tool Name | Download Link | Description |
|---|---|---|
| hvpp | https://github.com/wbenny/hvpp | |
| HyperBone | https://github.com/DarthTon/HyperBone | |
| HyperWin | https://github.com/amiryeshurun/HyperWin | |
| Hypervisor | https://github.com/Bareflank/hypervisor | |
| HyperPlatform | https://github.com/tandasat/HyperPlatform | |
| Hyper-V-Internals | https://github.com/gerhart01/Hyper-V-Internals | |
| Hypervisor-From-Scratch | https://github.com/SinaKarvandi/Hypervisor-From-Scratch | |
| KasperskyHook | https://github.com/iPower/KasperskyHook | |
| awesome-virtualization | https://github.com/Wenzel/awesome-virtualization | |
| ransomware_begone | https://github.com/ofercas/ransomware_begone |
Miscellaneous
| Tool Name | Download Link | Description |
|---|---|---|
| Divert | https://github.com/basil00/Divert | Redirect network traffic to user-mode applications for modification/dropping. |
| Blackbone | https://github.com/DarthTon/Blackbone | Kernel-mode injection techniques, including kernel memory injection. |
| NetWatch | https://github.com/huoji120/NetWatch | Threat-traffic detection platform; supports virtual memory patching. |
| x64_AOB_Search | https://github.com/wanttobeno/x64_AOB_Search | Enterprise-grade high-speed memory scanner (supports wildcards). |
| DuckMemoryScan | https://github.com/huoji120/DuckMemoryScan | Detects most so-called memory-only AV evasion shells. |
| FSDefender | https://github.com/Randomize163/FSDefender | File-system monitoring combined with cloud-backed backups. |
| AntiRansomware | https://github.com/clavis0x/AntiRansomware | Write-scanning anti-ransomware solution—prevents overwriting of files. |
| Lazy | https://github.com/moonAgirl/Lazy | (Malicious) ransomware terminator. |
| awesome-cheatsheets | https://github.com/skywind3000/awesome-cheatsheets/blob/master/tools/git.txt | Handy references for Python, Git, etc. |
CTF Resources
| Repository Name | Repository Link | Description |
|---|---|---|
| CTF-All-In-One | https://github.com/firmianay/CTF-All-In-One | |
| ctf-book | https://github.com/firmianay/ctf-book | Companion resources for the CTF Competition Guide (Pwn Edition). |
Penetration Testing
| Repository Name | Repository Link | Description |
|---|---|---|
| Web-Security-Learning | https://github.com/CHYbeta/Web-Security-Learning | |
| pentest | https://github.com/r0eXpeR/pentest | Tools and project reference for pivoting inside intranets. |
| K8tools | http://k8gege.org/p/72f1fea6.html | Collection of K8tools. |
| Awesome-Red-Teaming | https://github.com/yeyintminthuhtut/Awesome-Red-Teaming | List of Awesome Red-Teaming Resources. |
| Awesome-Hacking | https://github.com/Hack-with-Github/Awesome-Hacking | Curated lists for hackers. |
| awesome-web-hacking | https://github.com/infoslack/awesome-web-hacking | Penetration-testing knowledge base. |
Free Patent Search
| Repository Name | Repository Link | Description |
|---|---|---|
| Patent Information Service Platform | http://search.cnipr.com/ | |
| patents | <www.google.com/patents> | |
| incopat | <www.incopat.com> | |
| Baiten | https://www.baiten.cn/ | |
| rainpat | https://www.rainpat.com/ | |
| Duyan | https://www.uyanip.com/ |
Windows Guide
- Windows Guide
Windows
- [Win-to-go]
- [Understanding Windows File System]
- [Understanding Windows Processes]
- [Windows Related Resources]
- [Advanced Windows Management]
- [Windows Firewall Management - netsh]
- [Blocking Windows Network Traffic Acquisition]
- [Windows Troublesome Issues]
- [Understanding Windows Event Tracing (ETW)]
- [Understanding Windows Networking (WFP)]
- [windows-ipv6-management]
- [IPv6 Issues When Bridging Windows]
- [wireguard configuration]
window-message
- window-message
windows-message
Win-to-go
===
Windows To Go is convenient for portability, but several traditional Windows features are restricted.
- Preface
- Windows To Go Overview
- Differences between Windows To Go and traditional Windows installation
- Using Windows To Go for mobile work
- Preparing to install Windows To Go
- Hardware requirements
- USB hard drive or flash drive
- Host computer
- Checking architecture compatibility between host PC and Windows To Go drive
- Common Windows To Go questions
Preface
Windows To Go has existed for many years, yet there are so few Chinese-language resources on it—one can’t help but worry about the state of domestic IT documentation. The author has limited experience but is exposed to plenty of English development docs and hopes to lay some groundwork for future readers; any mistakes pointed out will be welcomed. For those comfortable reading English, comprehensive official documentation is available at the links below:
- Windows To Go Overview
- Best practice recommendations for Windows To Go
- Deployment considerations for Windows To Go
- Prepare your organization for Windows To Go
- Security and data protection considerations for Windows To Go
- Windows To Go: frequently asked questions
This post covers the overview and some common questions—mostly translations with the occasional author note (indicated by [J] until the next full stop) to prevent misinformation.
Windows To Go Overview
Windows To Go is a feature of Windows Enterprise and Education editions; it is not available in the Home edition used by most general consumers. It allows you to create a portable Windows system on a USB drive or hard disk. Windows To Go is not intended to replace traditional installation methods; its main purpose is to let people who frequently switch workspaces do so more efficiently. Before using Windows To Go, you need to be aware of the following:
- Differences between Windows To Go and traditional Windows installation
- Using Windows To Go for mobile work
- Preparing to install Windows To Go
- Hardware requirements
Differences between Windows To Go and traditional Windows installation
Windows To Go behaves almost like a normal Windows environment except for these differences:
- All internal drives except the USB device you’re running from are offline by default—invisible in File Explorer—to safeguard data. [J]You still have ways to bring those drives online and change their files.
- The Trusted Platform Module (TPM) is unavailable. TPM is tied to an individual PC to protect business data. [J]Most consumer machines don’t have it, but if your corporate laptop is domain-joined, it’s best not to use Windows To Go on it; otherwise, freshen up your résumé first.
- Hibernation is disabled by default in Windows To Go but can be re-enabled via Group Policy. [J]Many machines break USB connections during hibernation and cannot resume—Microsoft anticipated this and disabled it; there’s usually no reason to change that setting.
- Windows Restore is disabled. If the OS breaks, you’ll need to reinstall.
- Factory reset and Windows Reset are unavailable.
- In-place upgrades are not supported. The OS stays at whatever version it was installed as—you cannot go from Windows 7 to 8 or from Windows 10 RS1 to RS2.
Using Windows To Go for mobile work
Windows To Go can boot on multiple machines; the OS will automatically determine the needed drivers. Apps tightly coupled to specific hardware may fail to run. [J]ThinkPad track-pad control apps or fingerprint utilities, for example.
Preparing to install Windows To Go
You can use System Center Configuration Manager or standard Windows deployment tools such as DiskPart and Deployment Image Servicing and Management (DISM). Consider:
- Do you need to inject any drivers into the Windows To Go image?
- How will you store and sync data when switching between machines?
- 32-bit or 64-bit? [J]All new hardware supports 64-bit; 64-bit CPUs can run 32-bit OSes, but 32-bit CPUs cannot run 64-bit OSes. 64-bit systems also consume more disk and memory. If any target machine has a 32-bit CPU or less than 4 GB RAM, stick with 32-bit.
- What resolution should you use when remoting in from external networks?
Hardware requirements
USB hard drive or flash drive
Windows To Go is specifically optimized for certified devices:
- Optimizes USB devices for high random read/write, ensuring smooth daily use.
- Can boot Windows 7 and later from certified devices.
- Continues to enjoy OEM warranty support even while running Windows To Go. [J]The host PC’s warranty wasn’t mentioned.
Uncertified USB devices are not supported. [J]Try it and you’ll learn quickly why—it just won’t work. [J]Non-standard hacks (e.g., spoofing device IDs) are out there but outside scope.
Host computer (Host computer)
- Certified for Windows 7 and later.
- Windows RT systems are unsupported.
- Apple Macs are unsupported. [J]Even though the web is full of success stories on using Windows To Go on a Mac, the official stance is clear: no support.
Minimum specs for a host computer:
| Item | Requirement |
|---|---|
| Boot capability | Must support USB boot |
| Firmware | USB-boot option enabled |
| Processor architecture | Must match supported Windows To Go requirements |
| External USB hub | Not supported. The Windows To Go device must be plugged directly into the host |
| Processor | 1 GHz or faster |
| RAM | 2 GB or more |
| Graphics | DirectX 9 or later with WDDM 1.2 |
| USB port | USB 2.0 or later |
Checking architecture compatibility between host PC and Windows To Go drive
| Host PC Firmware Type | Host PC Processor Architecture | Compatible Windows To Go Image Architecture |
|---|---|---|
| Legacy BIOS | 32-bit | 32-bit only |
| Legacy BIOS | 64-bit | 32-bit and 64-bit |
| UEFI BIOS | 32-bit | 32-bit only |
| UEFI BIOS | 64-bit | 64-bit only |
Common Windows To Go questions
environment
Windows Subsystem Linux(WSL)
- _index
WSL Mirrored Network Mode Configuration Guide
Version Requirements
Current version status:
- Latest stable: 2.5.9 (known networking issues)
- Recommended version: 2.6.0 preview (full mirrored mode support)
Mode Comparison Analysis
| Feature | bridge mode (deprecated) | mirrored mode (recommended) |
|---|---|---|
| Protocol architecture | Dual-stack | Shared stack |
| IP address allocation | Independent IP (Windows + WSL) | Shared host IP |
| Port resources | Separate | Shared ports (conflict-avoidance required) |
| Network performance | Relatively heavy | Lightweight & efficient |
| Configuration complexity | Simple | Requires deep firewall policy setup |
Standard Configuration Steps
1. Network Mode Settings
Configure the base mode via WSL Settings app:
- Open the Settings app
- Select the Network tab
- Set network mode to Mirrored
- Apply the configuration and restart WSL
2. Firewall Policy Configuration
Run the complete policy configuration via PowerShell:
# Define the WSL VM GUID
$wslGuid = '{40E0AC32-46A5-438A-A0B2-2B479E8F2E90}'
# Configure firewall policies (execute in order)
Set-NetFirewallHyperVVMSetting -Name $wslGuid -Enabled True
Set-NetFirewallHyperVVMSetting -Name $wslGuid -DefaultInboundAction Allow
Set-NetFirewallHyperVVMSetting -Name $wslGuid -DefaultOutboundAction Allow
Set-NetFirewallHyperVVMSetting -Name $wslGuid -LoopbackEnabled True
Set-NetFirewallHyperVVMSetting -Name $wslGuid -AllowHostPolicyMerge True
# Verify configuration results
Get-NetFirewallHyperVVMSetting -Name $wslGuid
3. Port Mapping Validation
# Example: Check port 80 usage
Get-NetTCPConnection -LocalPort 80
Common Issue Troubleshooting
Issue 1: External Connections Fail
- Check step: All fields returned by
Get-NetFirewallHyperVVMSettingshould be True/Allow - Solution: Re-run the firewall policy configuration commands in order
Issue 2: Port Conflicts
- Check method: Use
netstat -anoto view port usage - Handling advice: Prefer to release ports occupied by Windows, or change the listening port in the WSL service
Validation Steps
- Start your WSL service (e.g., Nginx/Apache)
- Access from Windows host:
http://localhost:<port> - Access from LAN devices:
http://<host-ip>:<port>
References
wsl
Configure wsl
Remote access ssh
wsl
sudo apt install openssh-server
sudo nano /etc/ssh/sshd_config
/etc/ssh/sshd_config
...STUFF ABOVE THIS...
Port 2222
#AddressFamily any
ListenAddress 0.0.0.0
#ListenAddress ::
...STUFF BELOW THIS...
windows
service ssh start
netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=2222 connectaddress=172.23.129.80 connectport=2222
netsh advfirewall firewall add rule name="Open Port 2222 for WSL2" dir=in action=allow protocol=TCP localport=2222
netsh interface portproxy show v4tov4
netsh int portproxy reset all
Configure wsl
https://docs.microsoft.com/en-us/windows/wsl/wsl-config#configuration-setting-for-wslconfig
Set-Content -Path "$env:userprofile\\.wslconfig" -Value "
# Settings apply across all Linux distros running on WSL 2
[wsl2]
# Limits VM memory to use no more than 4 GB, this can be set as whole numbers using GB or MB
memory=2GB
# Sets the VM to use two virtual processors
processors=2
# Specify a custom Linux kernel to use with your installed distros. The default kernel used can be found at https://github.com/microsoft/WSL2-Linux-Kernel
# kernel=C:\\temp\\myCustomKernel
# Sets additional kernel parameters, in this case enabling older Linux base images such as Centos 6
# kernelCommandLine = vsyscall=emulate
# Sets amount of swap storage space to 8GB, default is 25% of available RAM
swap=1GB
# Sets swapfile path location, default is %USERPROFILE%\AppData\Local\Temp\swap.vhdx
swapfile=C:\\temp\\wsl-swap.vhdx
# Disable page reporting so WSL retains all allocated memory claimed from Windows and releases none back when free
pageReporting=false
# Turn off default connection to bind WSL 2 localhost to Windows localhost
localhostforwarding=true
# Disables nested virtualization
nestedVirtualization=false
# Turns on output console showing contents of dmesg when opening a WSL 2 distro for debugging
debugConsole=true
"
Virtual Memory Disk Setup
- Virtual Memory Disk Setup
Virtual Memory Disk Setup
Redirect Browser Cache to Virtual Disk
# Use ImDisk to create a virtual disk
# The following command creates a 4 GB virtual disk and mounts it as M: drive
imdisk -a -s 4G -m M: -p "/fs:ntfs /q /y"
rd /q /s "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Cache"
rd /q /s "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Code Cache"
md M:\Edge_Cache\
md M:\Edge_CodeCache\
mklink /D "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Cache" "M:\Edge_Cache\"
mklink /D "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Code Cache" "M:\Edge_CodeCache\"
# Restore browser cache to default location
rd "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Cache"
rd "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Code Cache"
md "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Cache"
md "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data\Default\Code Cache"
# Unmount the virtual disk
# To remove the virtual disk, use the following command
imdisk -D -m M:
vs-remote-debug
remote debug with visual studio
Remote debugging C++: https://docs.microsoft.com/en-us/visualstudio/debugger/remote-debugging-cpp?view=vs-2019
Attach debugging: https://docs.microsoft.com/en-us/visualstudio/debugger/attach-to-running-processes-with-the-visual-studio-debugger?view=vs-2019
Configure co-debugging program as a service: https://docs.microsoft.com/en-us/visualstudio/debugger/remote-debugging?view=vs-2019#bkmk_configureService
How to configure launch parameters: https://stackoverflow.com/questions/6740422/visual-studio-remote-debugging-a-service
Available parameters: https://social.msdn.microsoft.com/Forums/vstudio/en-US/174c2039-b316-455a-800e-18c0d93b74bc/visual-studio-2010-remote-debugger-settings-dont-persist?forum=vsdebug
Add your own task
"C:\Program Files\Microsoft Visual Studio 16.0\Common7\IDE\Remote Debugger\x64\msvsmon.exe"
Launch parameters
/noauth /anyuser /port:4045 /nosecuritywarn /timeout 360000
Dev machine connect: test0.example.com:4045
Remote access (developer mode must be enabled first): http://test0.example.com:50080/
How Many Principles of Design Patterns Are There?
最早总结的设计模式只有 5 个, 即SOLID:
单一职责原则 (Single Responsibility Principle, SRP):a class should have only one reason to change—i.e., only one responsibility.开闭原则 (Open/Closed Principle, OCP):software entities (classes, modules, functions, etc.) should be open for extension but closed for modification; in other words, change should be achieved by extension rather than by modifying existing code.里氏替换原则 (Liskov Substitution Principle, LSP):subtypes must be substitutable for their base types—i.e., derived classes must be able to replace their base classes without affecting program correctness.接口隔离原则 (Interface Segregation Principle, ISP):clients should not be forced to depend on interfaces they do not use. Large interfaces should be split into smaller, more specific ones so clients only need to know the methods they actually use.依赖倒置原则 (Dependency Inversion Principle, DIP):high-level modules should not depend on low-level modules; both should depend on abstractions. Abstractions should not depend on details; details should depend on abstractions.
后来增加了两个规则, 这些后加的规则相较来说更具体, 更有指导性. 我们从原则解释中可以看到SOLID描述应该怎么做, 后加的规则描述优先/最好怎么做.
合成/聚合复用原则 (Composition/Aggregation Reuse Principle, CARP):preference should be given to composition/aggregation over inheritance for reusing code.迪米特法则 (Law of Demeter, LoD):an object should have minimal knowledge of other objects—i.e., it should know as little as possible about their internal structure and implementation details.
除了上述提到的常见设计原则外,还有一些其他的设计原则,虽然不如前面提到的那些广为人知,但同样对软件设计和架构有重要的指导作用。 后续提出的这些规则, 有点画蛇添足, 至少我认为它们不反直觉, 不需要深入思考.
最少知识原则 (Principle of Least Knowledge, PoLK):also regarded as an extension of the Law of Demeter, it asserts that an object should acquire as little knowledge as possible about other objects. The concept originates from the 1987 “Law of Least Communication” proposed by Patricia Lago and Koos Visser.稳定依赖原则 (Stable Dependencies Principle, SDP):this principle holds that a design should ensure stable components do not depend on unstable ones—i.e., components with higher stability should depend less on lower-stability components. The idea stems from in-depth studies of relationships among components in software systems.稳定抽象原则 (Stable Abstraction Principle, SAP):in line with the Stable Dependencies Principle, this guideline aligns abstraction with stability: stable components should be abstract, while unstable components should be concrete. It helps maintain both stability and flexibility in the software system.
Cross-Platform Content Publishing Tool — A Review of "蚁小二"
Foreword
Lately, I’ve wanted to write a bit to diversify my income, so I scouted around the various creator platforms, hoping to earn something—if not cash, then at least some coins.
Putting aside the platforms themselves, writing requires a bit of brainpower, and crafting articles isn’t easy. Naturally, I don’t want to send each piece to only one outlet. When you publish on multiple platforms, however, you run into one very annoying problem: repeating the same task over and over again.
If every platform supported external links and Markdown, a simple copy-and-paste wouldn’t be painful. In reality, though, most don’t let you import Markdown—and all the more welcome news is that they do accept Word files. You can convert .md to .docx and then upload the .docx.
Another pain point is that each platform has you go through its own publishing page. I’d prefer to handle everything in batch. During my search, I came across a tool called “蚁小二.” Don’t worry—this isn’t a sales pitch. If the tool were genuinely indispensable, I’d be slow and stingy to share. The fact I’m sharing means I remain skeptical about its real value.
Supported Platforms

It claims one-click publishing to many platforms. The free tier I’m using allows five accounts—plenty for pure writing. For video creators this cap might be a lifesaver.
Experience with Text-Based Creator Platforms
Since I don’t produce videos at all, I’ll skip that part and focus solely on what it’s like for text creators.
- The editor resembles a familiar word processor: paragraphs, boldface, block quotes, underlines, strikethrough, italics, page breaks, indentation, and images.
- Hyperlinks are not supported.
- Tables are not supported.
- There’s no Markdown. You can work around this by copying from VS Code’s Markdown preview to retain some formatting.
- A loose abstraction for “many” platforms.
- A loose abstraction for “multiple accounts on one platform.”
One-click publishing is, admittedly, rather smooth. Still, when I want to check feedback, I still have to visit each platform.
I don’t normally browse these self-media sites—overall quality isn’t stellar—but the barrier to entry is lower than I expected. In the future I’ll post there as well; stay tuned.
This was my first time using the tool. I’m by no means an expert, clueless about what topics earn money or what the payouts look like. If any seasoned creators could point me in the right direction, I’d be deeply grateful.
Jianshu Writing Experience
Jianshu’s writing experience is only slightly better than Notepad.
Minimalist Note Management
This is the article-editing page, with only two levels of abstraction:
- notebook list
- note list
- editor
Fewer levels are both advantageous and problematic. Simple operations reduce cognitive load, yet they will eventually increase an author’s overhead in managing articles.
Difficult Image Uploading
For eight whole years, Jianshu has still not solved the external-image upload issue.
External linking only fails sometimes, and many image hosts allow empty or any referer—Jianshu doesn’t even try, claiming local upload is the “correct” way. One wonders if the operators have ever tried writing on other platforms.
It’s hard to believe any writer would stay on just one platform. If a platform can’t let creators copy and paste easily, it can only remain niche.
No Review Process
Jianshu doesn’t seem to review content; I’ve never seen any review status—you publish, and the post is instantly available. If a platform barely reviews its content, perhaps we could do this and that…
Random IP Geolocation
Jianshu hasn’t actually implemented IP geolocation; the IP address refreshes with a random update every time.