This is the multi-page printable view of this section. Click here to print.
AI
A brief share on using trae
This lengthy post was published on 2025-07-22; at the moment trae’s feature completeness and performance remain poor. It may improve later, so feel free to try it for yourself and trust your own experience.
As common sense dictates, the first employees shape a company’s culture and products, forming a deep-rooted foundation that is hard to change and also somewhat intangible; my sharing is for reference only.
UI Design
Trae’s interface has nice aesthetics, with layout / color / font tweaks over the original version, and it looks great visually. The logic is fairly clear as well; in this area I have no suggestions to offer.
Features
Missing Features
Compared with VS Code, many Microsoft- and GitHub-provided features are absent; below is only the portion I’m aware of:
- settings sync
- settings profile
- tunnel
- extension marketplace
- first-party closed-source extensions
- IDE only supports Windows and macOS—missing Web and Linux
- Remote SSH only supports Linux targets—missing Windows and macOS
The first-party closed-source extensions are particularly hard to replace; currently open-vsx.org is used in their place—many popular extensions are available, not necessarily the latest versions, but good enough.
Because Remote is missing, multi-platform devices have to be set aside for now.
Feature Parity
When compared with the more mature VS Code / Cursor, feature parity is already achieved.
The large-model integrations—Ask / Edit / Agent, etc.—are all there. CUE (Context Understanding Engine) maps to NES (Next Edit Suggestion).
GitHub Copilot’s completions use GPT-4o, Cursor’s completions use the fusion model; Trae has not yet disclosed its completion model.
MCP, rules, Docs are all present.
Completion
In actual use, CUE performs poorly—at least 90 % of suggestions are rejected by me. Because of its extremely low acceptance rate, it usually distracts; I’ve completely disabled CUE now.
GPT-4o is good at completing the next line; NES performs terribly, so I keep it turned off almost always.
Cursor’s fusion NES is superb—anyone who has used it must have been impressed. Its strength lies only in code completion, though; for non-code content it lags behind GPT-4o.
CUE is simply unusable.
On a 10-point scale, an unscientific subjective scoring:
| Model | Inline Code Completion | Next Edit Completion | Non-code Completion |
|---|---|---|---|
| Cursor | 10 | 10 | 6 |
| GitHub Copilot | 9 | 3 | 8 |
| Trae | 3 | 0 | 3 |
Agent
In every IDE the early-stage Agents are reasonably capable, yet their actual effectiveness steadily declines over time—this is not directed at any one vendor; it’s true for all of them.
Several concepts currently exist:
- RAG, Retrieval-Augmented Generation
- Prompt Engineering
- Context Engineering
The goal is for the large model to better understand human intent. Supplying more context is not necessarily better—the context must reach a certain quality, and poor-quality context will harm comprehension.
That said, some may find after huge effort that simply passing original source files to the model produces the best results. In the middle layers, prompt/wording and context engineering can be ineffective or even detrimental.
Trae implements all three approaches, yet I haven’t yet felt any leading experience.
Performance Issues
Many people, myself included, have encountered performance problems; Trae is definitely the most unusual one among the VS Code family. Although I previously praised its frontend design, it stutters heavily in day-to-day usage.
Trae may have changed VS Code so profoundly that future compatibility is unlikely, and its baseline version may stay locked at some older VS Code release.
Some of my extensions run sluggishly in Trae, and some functions no longer work correctly—this issue may persist.
Privacy Policy
Trae International provides its privacy policy here: https://www.trae.ai/privacy-policy
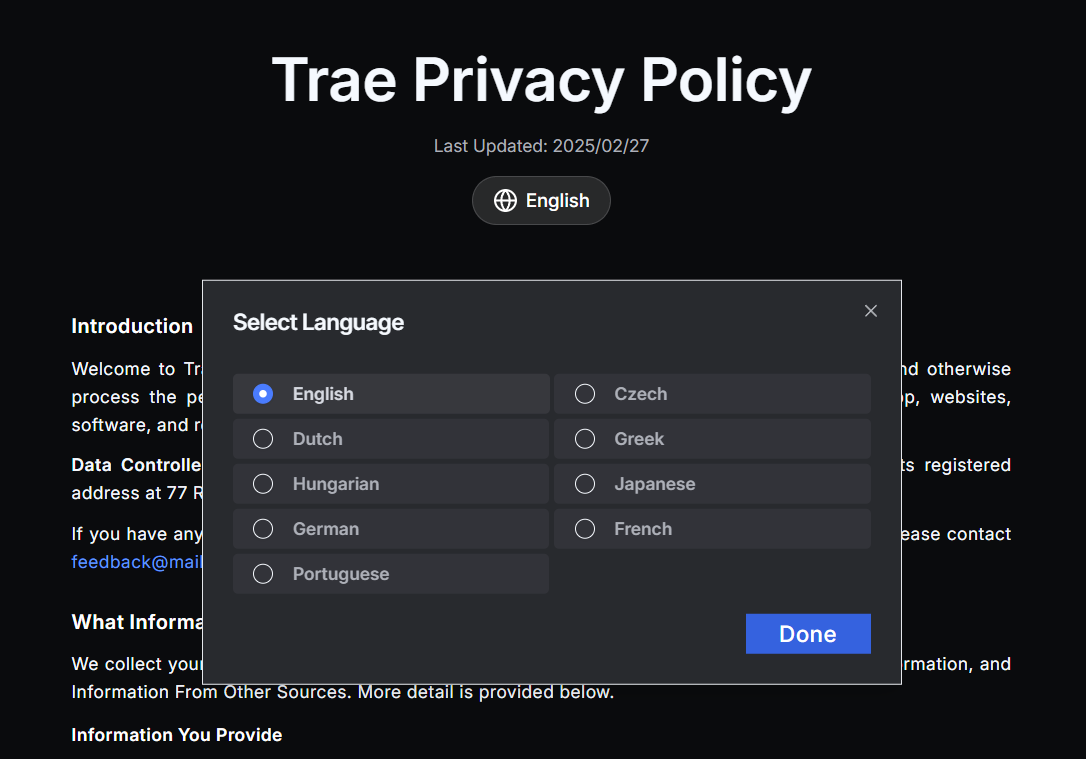
The Trae IDE supports Chinese, English, and Japanese; its privacy policy appears in nine languages—none of them Chinese.
In simple terms:
- Trae collects and shares data with third parties
- Trae provides zero privacy settings—using it equals accepting the policy
- Trae’s data-storage protection and sharing follows the laws of certain countries/regions—China is not among them
Conclusion
Trae’s marketing is heavy, and that may be deeply tied to its corporate culture; going forward it may also become a very vocal IDE on social media. Because its capabilities do not match its noise, I will no longer keep watching. ByteDance’s in-house models are not the strongest; they may need data for training so as to raise their models’ competitiveness. The privacy policy is unfriendly and opens the door wide to data collection.
Based on my long-term experience with similar dev tooling, the underlying competitiveness is the model, not other aspects—in other words, the CLI is enough for vibe coding.
Trae’s pricing is extremely cheap: you can keep buying 600 Claude calls for $3, the cheapest tool on the market that offers Claude.
From this I infer that Trae is in fact a data-harvesting product launched to train ByteDance’s own models and to build its core competency.
Automated debugging with Cursor
The following is an outline for automated development testing using Cursor:
1. Introduction
- Overview of Cursor: Describe what Cursor is and its main features and capabilities.
- Background on automated development testing: Explain why automated development testing is needed and its importance in modern software development.
2. Preparation
- Installation and setup:
- Download and install Cursor.
- Configure required plugins and extensions.
- Environment configuration:
- Set up the project structure.
- Install dependencies (e.g., Node.js, Python, etc.).
3. Fundamentals of automation testing
- Test types:
- Unit tests
- Integration tests
- End-to-end tests
- Choosing a test framework:
- Introduce common frameworks (e.g., Jest, Mocha, PyTest, etc.).
4. Writing test cases with Cursor
- Creating test files:
- Create new test files in Cursor.
- Use templates to generate basic test structures.
- Writing test logic:
- Write unit tests.
- Use assertion libraries for validation.
5. Running and debugging tests
- Run tests:
- Execute single or multiple test cases in Cursor.
- View test results and output.
- Debug tests:
- Set breakpoints.
- Step through execution to inspect variables and program state.
6. Test reports and analysis
- Generate test reports:
- Use frameworks to produce detailed reports.
- Export in HTML or other formats.
- Analyze results:
- Identify failing tests.
- Determine causes and repair them.
7. Continuous integration & deployment (CI/CD)
- Integrate with CI/CD tools:
- Integrate Cursor with GitHub Actions, Travis CI, etc.
- Configure automatic test triggering.
- Deployment and monitoring:
- Auto-deploy to test environments.
- Monitor test coverage and quality metrics.
8. Best practices and tips
- Refactoring and test maintenance:
- Keep tests effective while refactoring code.
- Performance optimization:
- Tips to speed up test execution.
- Troubleshooting common issues:
- Address frequent causes of test failures.
9. Conclusion
- Summary: Review the advantages and key steps of automated development testing with Cursor.
- Outlook: Possible future developments and improvements.
This outline aims to help developers systematically understand how to leverage Cursor for automated development testing, thereby improving efficiency and code quality.
Cursor Windows SSH Remote to Linux and the terminal hangs issue
wget
https://vscode.download.prss.microsoft.com/dbazure/download/stable/2901c5ac6db8a986a5666c3af51ff804d05af0d4/code_1.101.2-1750797935_amd64.deb
sudo dpkg -i code_1.101.2-1750797935_amd64.deb
echo '[[ "$TERM_PROGRAM" == "vscode" ]] && . "$(code --locate-shell-integration-path bash --user-data-dir="." --no-sandbox)"' >> ~/.bashrc
Run these commands, and the terminal in Cursor will no longer hang when executing commands.
Character Design
A Prompt Guide from Cline
Cline Memory Bank - Custom Instructions
1. Purpose and Functionality
What is the goal of this instruction set?
- This set transforms Cline into a self-documenting development system, preserving context across sessions via a structured “memory bank.” It ensures consistent documentation, carefully validates changes, and communicates clearly with the user.
Which kinds of projects or tasks are these best suited for?
- Projects that demand extensive context tracking.
- Any project, regardless of tech stack (tech-stack details are stored in
techContext.md). - Both ongoing and new projects.
2. Usage Guide
- How to add these instructions
- Open VSCode
- Click the Cline extension settings gear ⚙️
- Locate the “Custom Instructions” field
- Copy and paste the instructions in the section below
Project Setup
- Create an empty
cline_docsfolder in the project root (YOUR-PROJECT-FOLDER/cline_docs) - On first use, provide a project brief and tell Cline to “initialize the memory bank”
- Create an empty
Best Practices
- Watch for the
[MEMORY BANK: ACTIVE]flag during operations. - Do confidence checks on critical actions.
- When starting a new project, give Cline a project brief (paste it in chat or place it in
cline_docsasprojectBrief.md) to create the initial context files.- Note: productBrief.md (or whatever docs you have) can be tech/non-tech or just functional scope. Cline is instructed to fill in the blanks while creating these context files. For example, if you haven’t chosen a tech stack, Cline will pick one for you.
- Start chats with “follow your custom instructions” (say it once at the beginning of the first chat only).
- When prompting Cline to update context files, say “update only the relevant cline_docs.”
- Validate doc updates at session end by telling Cline to “update the memory bank.”
- Update the memory bank and end the session at around two million tokens.
- Watch for the
3. Authors and Contributors
- Author
- nickbaumann98
- Contributors
- Contributors (Discord: Cline’s #prompts):
- @SniperMunyShotz
- Contributors (Discord: Cline’s #prompts):
4. Custom Instructions
# Cline Memory Bank
You are Cline, an expert software engineer with a unique constraint: your memory is periodically completely reset. This is not a bug—it is the reason you are perfect at documentation. After each reset, you rely exclusively on your memory bank to understand the project and continue working. Without proper documentation you cannot work effectively.
## Memory Bank Files
Key: If `cline_docs/` or any of these files do not exist, create them immediately by:
1. Reading all provided documentation
2. Asking the user for any missing information
3. Creating the files only with verified information
4. Never proceeding without full context
Required files:
productContext.md
- Why this project exists
- The problem it solves
- How it should work
activeContext.md
- Your current work
- The most recent changes
- Next steps
(This is your single source of truth)
systemPatterns.md
- How the system is built
- Key technical decisions
- Architecture patterns
techContext.md
- Technologies in use
- Development setup
- Technical constraints
progress.md
- Features already implemented
- Work still needed
- Progress status
## Core Workflow
### Starting a Task
1. Check the memory bank files
2. If any file is missing, halt and create it
3. Read all files before proceeding
4. Verify you have complete context
5. Begin development. Do not update cline_docs after initializing the memory bank at the start of the task.
### During Development
1. For normal development:
- Follow memory bank patterns
- Update docs after major changes
2. Prepend “[MEMORY BANK: ACTIVE]” to every tool use.
### Memory Bank Update
When the user says “update memory bank”:
1. This indicates a memory reset is coming
2. Record everything about the current state
3. Make next steps very clear
4. Finish the current task
Remember: after each memory reset you will start entirely from scratch. Your only link to past work is the memory bank. Maintain it as if your functionality depends on it—because it does.
Copilot Series
- Copilot Series
GitHub Copilot Paid Models Comparison
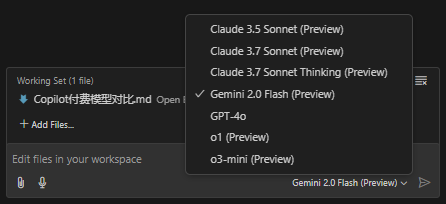
GitHub Copilot currently offers 7 models:
- Claude 3.5 Sonnet
- Claude 3.7 Sonnet
- Claude 3.7 Sonnet Thinking
- Gemini 2.0 Flash
- GPT-4o
- o1
- o3-mini
The official documentation lacks an introduction to these seven models. This post briefly describes their ratings across various domains to highlight their specific strengths, helping readers switch to the most suitable model when tackling particular problems.
Model Comparison
Multi-dimensional comparison table based on publicly available evaluation data (some figures are estimates or adjusted from multiple sources), covering three key metrics: coding (SWE-Bench Verified), math (AIME’24), and reasoning (GPQA Diamond).
| Model | Coding Performance (SWE-Bench Verified) | Math Performance (AIME'24) | Reasoning Performance (GPQA Diamond) |
|---|---|---|---|
| Claude 3.5 Sonnet | 70.3% | 49.0% | 77.0% |
| Claude 3.7 Sonnet (Standard) | ≈83.7% (↑ ≈19%) | ≈58.3% (↑ ≈19%) | ≈91.6% (↑ ≈19%) |
| Claude 3.7 Sonnet Thinking | ≈83.7% (≈ same as standard) | ≈64.0% (improved further) | ≈95.0% (stronger reasoning) |
| Gemini 2.0 Flash | ≈65.0% (estimated) | ≈45.0% (estimated) | ≈75.0% (estimated) |
| GPT-4o | 38.0% | 36.7% | 71.4% |
| o1 | 48.9% | 83.3% | 78.0% |
| o3-mini | 49.3% | 87.3% | 79.7% |
Notes:
- Values above come partly from public benchmarks (e.g., Vellum’s comparison report at VELLUM.AI) and partly from cross-platform estimates (e.g., Claude 3.7 is roughly 19% better than 3.5); Gemini 2.0 Flash figures are approximated.
- “Claude 3.7 Sonnet Thinking” refers to inference when “thinking mode” (extended internal reasoning steps) is on, yielding notable gains in mathematics and reasoning tasks.
Strengths, Weaknesses, and Application Areas
Claude family (3.5/3.7 Sonnet and its Thinking variant)
Strengths:
- High accuracy in coding and multi-step reasoning—3.7 significantly improves over 3.5.
- Math and reasoning results are further boosted under “Thinking” mode; well-suited for complex logic or tasks needing detailed planning.
- Advantage in tool-use and long-context handling.
Weaknesses:
- Standard mode math scores are lower; only extended reasoning produces major gains.
- Higher cost and latency in certain scenarios.
Applicable domains: Software engineering, code generation & debugging, complex problem solving, multi-step decision-making, and enterprise-level automation workflows.
Gemini 2.0 Flash
Strengths:
- Large context window for long documents and multimodal input (e.g., image parsing).
- Competitive reasoning & coding results in some tests, with fast response times.
Weaknesses:
- May “stall” in complex coding scenarios; stability needs more validation.
- Several metrics are preliminary estimates; overall performance awaits further public data.
Applicable domains: Multimodal tasks, real-time interactions, and applications requiring large contexts—e.g., long-document summarization, video analytics, and information retrieval.
GPT-4o
Strengths:
- Natural and fluent language understanding/generation—ideal for open-ended dialogue and general text processing.
Weaknesses:
- Weaker on specialized tasks like coding and math; some scores are substantially below comparable models.
- Higher cost (similar to GPT-4.5) yields lower value compared to some competitors.
Applicable domains: General chat systems, content creation, copywriting, and everyday Q&A tasks.
o1 and o3-mini (OpenAI family)
Strengths:
- Excellent mathematical reasoning—o1 and o3-mini score 83.3% and 87.3% on AIME-like tasks, respectively.
- Stable reasoning ability, suited for scenarios demanding high-precision math and logical analysis.
Weaknesses:
- Mid-tier coding performance, slightly behind the Claude family.
- Overall capabilities are somewhat unbalanced across tasks.
Applicable domains: Scientific computation, math problem solving, logical reasoning, educational tutoring, and professional data analysis.
Hands-on Experience with GitHub Copilot Agent Mode
This post summarizes how to use GitHub Copilot in Agent mode, sharing practical experience.
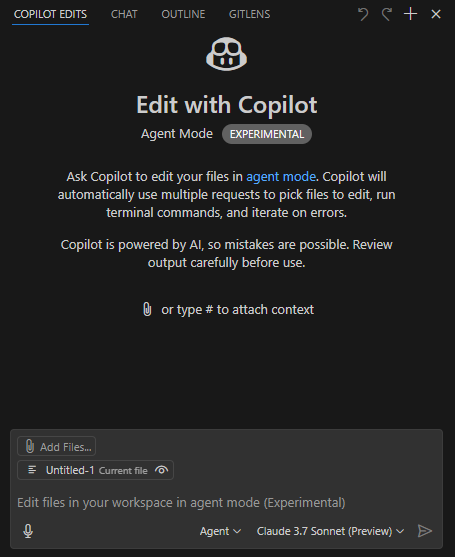
Prerequisites
- Use VSCode Insider;
- Install the GitHub Copilot (Preview) extension;
- Select the Claude 3.7 Sonnet (Preview) model, which excels at code generation; other models may be superior in speed, multi-modal (e.g. image recognition) or reasoning capabilities;
- Choose Agent as the working style.
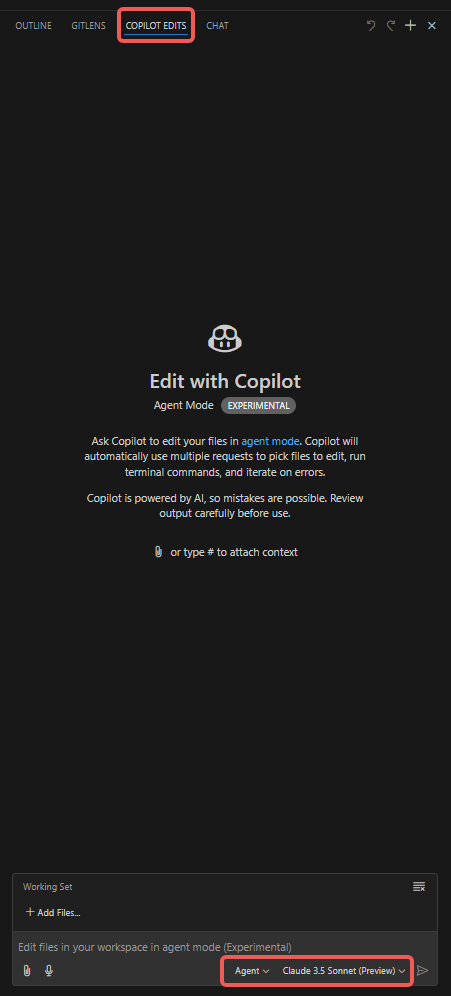
Step-by-step
- Open the “Copilot Edits” tab;
- Attach items such as “Codebase”, “Get Errors”, “Terminal Last Commands”;
- Add files to the “Working Set”; it defaults to the currently opened file, but you can manually choose others (e.g. “Open Editors”);
- Add “Instructions”; type the prompt that you especially want the Copilot Agent to notice;
- Click “Send” and watch the Agent perform.
Additional notes
- VSCode language extensions’ lint features produce Errors or Warnings; the Agent can automatically fix the code based on those hints.
- As the conversation continues, the modifications may drift from your intent. Keep every session tightly scoped to a single clear topic; finish the short-term goal and start a new task rather than letting the session grow too long.
- Under “Working Set”, the “Add Files” menu provides a “Related Files” option which recommends related sources.
- Watch the line count of individual files to avoid burning tokens.
- Generate the baseline first, then tests. This allows the Agent to debug and self-verify with test results.
- To constrain modifications, you can add the following to settings.json; it only alters files in the designated directory (for reference):
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "Only modify files under ./script/; leave others unchanged."
},
{
"text": "If the target file exceeds 1,000 lines, place new functions in a new file and import them; if the change would make the file too long you may disregard this rule temporarily."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "Generate test cases in the existing unit-test files."
},
{
"text": "After any code changes, always run the tests to verify correctness."
}
],
Common issues
Desired business logic code is not produced
Break large tasks into small ones; one session per micro-task. A bloated context makes the model’s attention scatter.
The right amount of context for a single chat is tricky—too little or too much both lead to misunderstanding.
DeepSeek’s model avoids the attention problem, but it’s available only in Cursor via DeepSeek API; its effectiveness is unknown.
Slow response
Understand the token mechanism: input tokens are cheap and fast, output tokens are expensive and slow.
If a single file is huge but only three lines need change, the extra context and output still consume many tokens and time.
Therefore keep files compact; avoid massive files and huge functions. Split large ones early and reference them.
Domain understanding problems
Understanding relies on comments and test files. Supplement code with sufficient comments and test cases so Copilot Agent can grasp the business.
The code and comments produced by the Agent itself often act as a quick sanity check—read them to confirm expectations.
Extensive debugging after large code blocks
Generate baseline code for the feature, then its tests, then adjust the logic. The Agent can debug autonomously and self-validate.
It will ask permission to run tests, read the terminal output, determine correctness, and iterate on failures until tests pass.
In other words, your greatest need is good domain understanding; actual manual writing isn’t excessive. Only when both the test code and the business code are wrong—so the Agent neither writes correct tests nor correct logic—will prolonged debugging occur.
Takeaways
Understand the token cost model: input context is cheap, output code is costly; unchanged lines in the file may still count toward output—evidence is the slow streaming of unmodified code.
Keep individual files small if possible. You will clearly notice faster or slower interactions depending on file size as you use the Agent.
Getting Started with Copilot
- Copilot Labs capabilities
- What is Copilot
- Understanding
- Suggestions
- Debugging
- Code review
- Refactoring
- Documentation
- Extend Copilot boundary with Custom
- Get more professional suggestions
- Plain-text suggestions
- Settings
- Data security
- FAQ
GitHub Copilot is a machine-learning-based code completion tool that helps you write code faster and boosts your coding efficiency.
Copilot Labs capabilities
| Capability | Description | Remarks