- Copilot Series
This is the multi-page printable view of this section. Click here to print.
Copilot Series
- GitHub Copilot Paid Models Comparison
- Hands-on Experience with GitHub Copilot Agent Mode
- Getting Started with Copilot
GitHub Copilot Paid Models Comparison
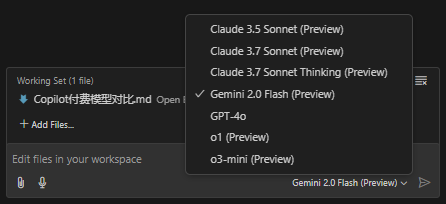
GitHub Copilot currently offers 7 models:
- Claude 3.5 Sonnet
- Claude 3.7 Sonnet
- Claude 3.7 Sonnet Thinking
- Gemini 2.0 Flash
- GPT-4o
- o1
- o3-mini
The official documentation lacks an introduction to these seven models. This post briefly describes their ratings across various domains to highlight their specific strengths, helping readers switch to the most suitable model when tackling particular problems.
Model Comparison
Multi-dimensional comparison table based on publicly available evaluation data (some figures are estimates or adjusted from multiple sources), covering three key metrics: coding (SWE-Bench Verified), math (AIME’24), and reasoning (GPQA Diamond).
| Model | Coding Performance (SWE-Bench Verified) | Math Performance (AIME'24) | Reasoning Performance (GPQA Diamond) |
|---|---|---|---|
| Claude 3.5 Sonnet | 70.3% | 49.0% | 77.0% |
| Claude 3.7 Sonnet (Standard) | ≈83.7% (↑ ≈19%) | ≈58.3% (↑ ≈19%) | ≈91.6% (↑ ≈19%) |
| Claude 3.7 Sonnet Thinking | ≈83.7% (≈ same as standard) | ≈64.0% (improved further) | ≈95.0% (stronger reasoning) |
| Gemini 2.0 Flash | ≈65.0% (estimated) | ≈45.0% (estimated) | ≈75.0% (estimated) |
| GPT-4o | 38.0% | 36.7% | 71.4% |
| o1 | 48.9% | 83.3% | 78.0% |
| o3-mini | 49.3% | 87.3% | 79.7% |
Notes:
- Values above come partly from public benchmarks (e.g., Vellum’s comparison report at VELLUM.AI) and partly from cross-platform estimates (e.g., Claude 3.7 is roughly 19% better than 3.5); Gemini 2.0 Flash figures are approximated.
- “Claude 3.7 Sonnet Thinking” refers to inference when “thinking mode” (extended internal reasoning steps) is on, yielding notable gains in mathematics and reasoning tasks.
Strengths, Weaknesses, and Application Areas
Claude family (3.5/3.7 Sonnet and its Thinking variant)
Strengths:
- High accuracy in coding and multi-step reasoning—3.7 significantly improves over 3.5.
- Math and reasoning results are further boosted under “Thinking” mode; well-suited for complex logic or tasks needing detailed planning.
- Advantage in tool-use and long-context handling.
Weaknesses:
- Standard mode math scores are lower; only extended reasoning produces major gains.
- Higher cost and latency in certain scenarios.
Applicable domains: Software engineering, code generation & debugging, complex problem solving, multi-step decision-making, and enterprise-level automation workflows.
Gemini 2.0 Flash
Strengths:
- Large context window for long documents and multimodal input (e.g., image parsing).
- Competitive reasoning & coding results in some tests, with fast response times.
Weaknesses:
- May “stall” in complex coding scenarios; stability needs more validation.
- Several metrics are preliminary estimates; overall performance awaits further public data.
Applicable domains: Multimodal tasks, real-time interactions, and applications requiring large contexts—e.g., long-document summarization, video analytics, and information retrieval.
GPT-4o
Strengths:
- Natural and fluent language understanding/generation—ideal for open-ended dialogue and general text processing.
Weaknesses:
- Weaker on specialized tasks like coding and math; some scores are substantially below comparable models.
- Higher cost (similar to GPT-4.5) yields lower value compared to some competitors.
Applicable domains: General chat systems, content creation, copywriting, and everyday Q&A tasks.
o1 and o3-mini (OpenAI family)
Strengths:
- Excellent mathematical reasoning—o1 and o3-mini score 83.3% and 87.3% on AIME-like tasks, respectively.
- Stable reasoning ability, suited for scenarios demanding high-precision math and logical analysis.
Weaknesses:
- Mid-tier coding performance, slightly behind the Claude family.
- Overall capabilities are somewhat unbalanced across tasks.
Applicable domains: Scientific computation, math problem solving, logical reasoning, educational tutoring, and professional data analysis.
Hands-on Experience with GitHub Copilot Agent Mode
This post summarizes how to use GitHub Copilot in Agent mode, sharing practical experience.
This post summarizes how to use GitHub Copilot in Agent mode, sharing practical experience.
Prerequisites
- Use VSCode Insider;
- Install the GitHub Copilot (Preview) extension;
- Select the Claude 3.7 Sonnet (Preview) model, which excels at code generation; other models may be superior in speed, multi-modal (e.g. image recognition) or reasoning capabilities;
- Choose Agent as the working style.
Step-by-step
- Open the “Copilot Edits” tab;
- Attach items such as “Codebase”, “Get Errors”, “Terminal Last Commands”;
- Add files to the “Working Set”; it defaults to the currently opened file, but you can manually choose others (e.g. “Open Editors”);
- Add “Instructions”; type the prompt that you especially want the Copilot Agent to notice;
- Click “Send” and watch the Agent perform.
Additional notes
- VSCode language extensions’ lint features produce Errors or Warnings; the Agent can automatically fix the code based on those hints.
- As the conversation continues, the modifications may drift from your intent. Keep every session tightly scoped to a single clear topic; finish the short-term goal and start a new task rather than letting the session grow too long.
- Under “Working Set”, the “Add Files” menu provides a “Related Files” option which recommends related sources.
- Watch the line count of individual files to avoid burning tokens.
- Generate the baseline first, then tests. This allows the Agent to debug and self-verify with test results.
- To constrain modifications, you can add the following to settings.json; it only alters files in the designated directory (for reference):
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "Only modify files under ./script/; leave others unchanged."
},
{
"text": "If the target file exceeds 1,000 lines, place new functions in a new file and import them; if the change would make the file too long you may disregard this rule temporarily."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "Generate test cases in the existing unit-test files."
},
{
"text": "After any code changes, always run the tests to verify correctness."
}
],
Common issues
Desired business logic code is not produced
Break large tasks into small ones; one session per micro-task. A bloated context makes the model’s attention scatter.
The right amount of context for a single chat is tricky—too little or too much both lead to misunderstanding.
DeepSeek’s model avoids the attention problem, but it’s available only in Cursor via DeepSeek API; its effectiveness is unknown.
Slow response
Understand the token mechanism: input tokens are cheap and fast, output tokens are expensive and slow.
If a single file is huge but only three lines need change, the extra context and output still consume many tokens and time.
Therefore keep files compact; avoid massive files and huge functions. Split large ones early and reference them.
Domain understanding problems
Understanding relies on comments and test files. Supplement code with sufficient comments and test cases so Copilot Agent can grasp the business.
The code and comments produced by the Agent itself often act as a quick sanity check—read them to confirm expectations.
Extensive debugging after large code blocks
Generate baseline code for the feature, then its tests, then adjust the logic. The Agent can debug autonomously and self-validate.
It will ask permission to run tests, read the terminal output, determine correctness, and iterate on failures until tests pass.
In other words, your greatest need is good domain understanding; actual manual writing isn’t excessive. Only when both the test code and the business code are wrong—so the Agent neither writes correct tests nor correct logic—will prolonged debugging occur.
Takeaways
Understand the token cost model: input context is cheap, output code is costly; unchanged lines in the file may still count toward output—evidence is the slow streaming of unmodified code.
Keep individual files small if possible. You will clearly notice faster or slower interactions depending on file size as you use the Agent.
Getting Started with Copilot
- Copilot Labs capabilities
- What is Copilot
- Understanding
- Suggestions
- Debugging
- Code review
- Refactoring
- Documentation
- Extend Copilot boundary with Custom
- Get more professional suggestions
- Plain-text suggestions
- Settings
- Data security
- FAQ
GitHub Copilot is a machine-learning-based code completion tool that helps you write code faster and boosts your coding efficiency.
Copilot Labs capabilities
| Capability | Description | Remarks